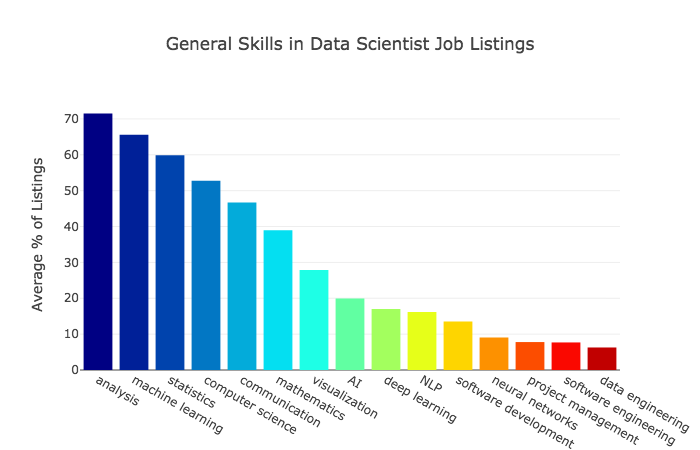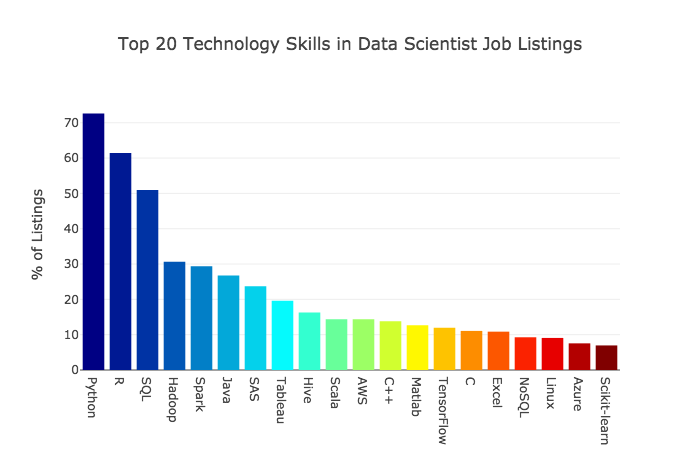
First of all, if you’re interested in a one-day conference that also gets you a chance to enjoy Florida’s warm winter and Disney World as well, check out DevFest Florida 2019. It takes place on Saturday, January 19, 2019, and I’ll be giving the Jumping into Jupyter Notebooks presentation, which will largely be a hands-on code-along-with-me exercise (or just watch, if you like) showing just what you can do with a Jupyter notebook, Python, and some data. If you know a little Python and are new to Jupyter notebooks, data science, or both, you’ll want to catch my presentation!

At this point, you might be asking “What are Jupyter Notebooks, anyway?”

Jupyter notebooks are a kind of computational notebook, a class of software that creates documents that mix:
- Stuff that you’d expect to find in a typical document, such text, pictures, and multimedia, and
- stuff that you wouldn’t expect to find in a typical document, such as code and its output.
To borrow a paragraph from an article that just appeared in nature, Why Jupyter is data scientists’ computational notebook of choice:
Jupyter is a free, open-source, interactive web tool known as a computational notebook, which researchers can use to combine software code, computational output, explanatory text and multimedia resources in a single document. Computational notebooks have been around for decades, but Jupyter in particular has exploded in popularity over the past couple of years. This rapid uptake has been aided by an enthusiastic community of user–developers and a redesigned architecture that allows the notebook to speak dozens of programming languages — a fact reflected in its name, which was inspired, according to co-founder Fernando Pérez, by the programming languages Julia (Ju), Python (Py) and R.
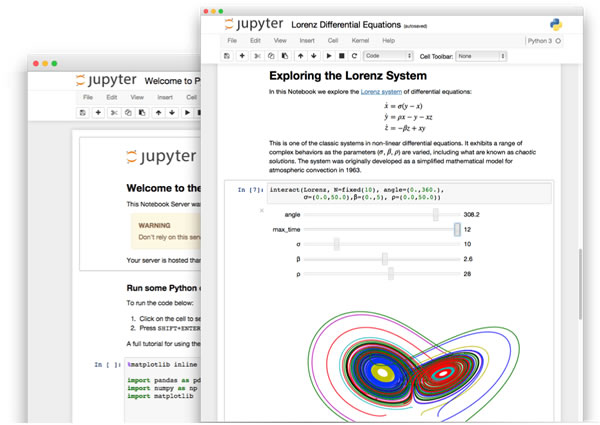
You may want to think of Jupyter notebooks as a wiki with a REPL. Its contents are divided into cells, which contain either:
- Narrative content, which you enter in Markdown, and
- Code — and if it runs, its output — which you can enter in Python or nearly four dozen other programming languages.
Jupyter notebooks’ format lends itself well to a number of research and educational uses. Once again, from the nature article:
Computational notebooks are essentially laboratory notebooks for scientific computing. Instead of pasting, say, DNA gels alongside lab protocols, researchers embed code, data and text to document their computational methods. The result, says Jupyter co-creator Brian Granger at California Polytechnic State University in San Luis Obispo, is a “computational narrative” — a document that allows researchers to supplement their code and data with analysis, hypotheses and conjecture.
For data scientists, that format can drive exploration. Notebooks, Barba says, are a form of interactive computing, an environment in which users execute code, see what happens, modify and repeat in a kind of iterative conversation between researcher and data. They aren’t the only forum for such conversations — IPython, the interactive Python interpreter on which Jupyter’s predecessor, IPython Notebook, was built, is another. But notebooks allow users to document those conversations, building “more powerful connections between topics, theories, data and results”, Barba says.
Researchers can also use notebooks to create tutorials or interactive manuals for their software. This is what Mackenzie Mathis, a systems neuroscientist at Harvard University in Cambridge, Massachusetts, did for DeepLabCut, a programming library her team developed for behavioural-neuroscience research. And they can use notebooks to prepare manuscripts, or as teaching aids. Barba, who has implemented notebooks in every course she has taught since 2013, related at a keynote address in 2014 that notebooks allow her students to interactively engage with — and absorb material from — lessons in a way that lectures cannot match. “IPython notebooks are really a killer app for teaching computing in science and engineering,” she said.
Ed. note: Before they were called Jupyter notebooks, they were called IPython notebooks.
Jupyter notebooks have recently received big boosts from big names. One of them is economist Paul Romer, who won the 2018 Nobel Prize in Economics — he’s a convert from Mathematica to Python and Jupyter notebooks:

Another big Jupyter booster isn’t from academia — it’s Netflix, where Jupyter notebooks are the most popular data tool:
Keep an eye on Jupyter notebooks. I’m pretty sure you’ll see them more often quite soon.
Getting into Jupyter notebooks
If you’re interested in trying them out, you may find these links handy: