Yesterday, Anitra and I were flying back to Tampa from New York’s LaGuardia Airport, and I noticed that most of the ads flashing on the billboard screen overlooking our departure lounge were for AI companies or products.
There were two different ads for Codex (one pictured above, one below)…
Monday, 7/27, is the day when we celebrate the techies and tech companies in the 727 area code: 727 Tech Day!
727 Tech Day is a one-day, all-in celebration of the St. Pete / Clearwater / Pinellas tech community, presented by the folks behind Tampa Bay Tech Week (with HyLo Innovation and W3RTech). If TBTW is the five-day, five-neighborhood sprawl, then 727 Tech Day as the encore focused on a single Tampa Bay county, with everybody in the same few rooms.
If you’re anywhere near the 727 and you build systems or software for a living, this is the easiest “yes” on your calendar this week.
The essentials
When: Monday, July 27, 2026
Where: Clearwater and St. Pete. It’s a venue-hop (details below)!
Vibe: Panels, hands-on workshops, a lot of open networking, and an evening that keeps going
727 Tech Day moves around the county!
This isn’t a sit-in-one-ballroom-until-4pm situation. The day migrates across Clearwater and St. Pete, which is either a feature or a step-count challenge depending on your mood:
Sunrise yoga on the rooftop at Station House to kick things off. Yes, yoga. At a tech event. Bring your own mat or grab one onsite. I’m told no other tech event in Florida opens like this, and I believe it.
Morning sessions at Collaborative Labs (over at St. Petersburg College).
Afternoon sessions at NOVA 535 in downtown St. Pete.
Happy Hour Networking at 4 PM at the St. Pete Athletic Club, with three hours of the good stuff (founders, operators, investors, community folks, all in one place).
Closing Night at 7 PM at The Estate, because “conversations to activations” apparently requires at least one iconic venue and a proper send-off.
Because this is our scene! It shows up best when we show up. 727 Tech Day is pitched as “no filler, no fluff”. The afternoon track alone, which is a build-something-real AI workshop plus three panels that all promise to separate signal from hype, is worth the trip. Add the networking window and the closing night, and you’ve got a full day of the people you actually want to run into.
I’ll be around. Come say hi! I’m the one with the accordion energy and strong opinions about zero-trust networking.
Tuesday, July 7th, 2026: If you’re on Claude Pro (the $20/month plan), Claude Max (the $100/month plan), or Claude Team ($25/user/month for Standard, $150/user/month for Premium), it’s your last day to use Claude Fable 5 bundled within your existing subscription limits. Starting tomorrow, you’ll need metered usage credits to get your paws on that sweet super-inference.
I suspect a lot of power users are going to be mainlining Fable 5 today; I myself will be availing myself of it via NetFoundry’s team plan (hey, if a company offers a perk, you use it!).
If you’re having trouble coming up with ideas for what to do with Fable 5 on this last day, I have suggestions:
Top (and obvious) priority: Use it to bring whatever Claude 5-based work to a state where you can hand if off to another model or human.
Treat it like the member of the group project who did all the work and is now moving far away. Have it walk you through any code that you asked it to generate that you don’t understand.
Devote a day a week to sharpening a skill that you’ve been outsourcing to Fable 5. Not “donkey work,” but an actual skill that you don’t have (yet).
Run the same hard task on Fable 5 and Opus 4.8 side by side. You’ll have a much better idea whether $10/$50-per-million-token price tag is justified for your workloads.
In the spirit of “meta”, I also asked Fable 5 what one should do on the last “free” day of Fable 5. Its answers:
Feed it the scariest codebase you have access to. The multi-repo, “the guy who wrote this left in 2019” kind. Fable 5’s benchmark edge is agentic coding and security audits, so this is the one day you can get a frontier-tier code review without doing token math in your head.
Run one genuinely long agentic task end to end. Not “write me a function” — more like “plan, scaffold, build, and test this MVP.” Long-horizon work is the whole point of the Mythos tier; short tasks reportedly come out nearly identical to Opus 4.8, which is like renting a Ferrari to drive to the mailbox.
Do the research brief for a decision you’ve been avoiding. Tech stack choice, framework migration, “should we self-host this” — anything with high decision value, lots of context, and many moving parts. That’s where the extra capability actually shows up.
Audit your docs the way an AI reads them. Hand it your entire documentation set and ask what an LLM would get wrong, miss, or hallucinate about your product.
Throw a big, ugly dataset at it. The CSV graveyard you’ve been meaning to analyze since Q1. Dense, messy, multi-step data work is squarely in its wheelhouse.
I also asked for some of the answers to be impractical and humorous. Its answers:
Ask it to explain the month it just had. Launched June 9, hit with a US export-control directive on June 12, suspended globally within 90 minutes, cleared and restored July 1. Few software products have a redemption arc; fewer can narrate their own.
Use the most expensive generally available AI model in history to write your grocery list. Pure decadence. The token cost of “eggs, milk, jalapeños” has never been higher, and it never will be again. Probably.
Have it arrange “Master of Puppets” for solo accordion. Is this a good use of Mythos-class reasoning? No. Will I do it convincingly? Also possibly no. But it’s free until midnight. [This one seems to have been aimed directly at me.]
Ask Fable 5 itself when it’s coming back to subscriptions, then screenshot its diplomatic non-answer for posterity. (Anthropic’s actual answer: “when sufficient capacity allows.” My answer would be roughly the same, but with more charm.)
A scene from The Ultimate Computer, a newly-relevant episode of Star Trek (the original series).
Is it just me, or would you agree that LLMs should refer to themselves as “this unit” instead of “I”, just like the AIs on the original Star Trek series did?
I think it might help prevent more people from going down the LLM rabbit hole.
I don’t need to tell you that AI’s already replacing jobs (or at least being used as an excuse), reshaping industries, and rewriting the rules of the workforce and the ways we work. Wouldn’t it be nice to get some perspective?
Join us this Tuesday! On the panel will be:
Sam Kasimalla as the host. You’ll know him from all sorts of local events, including Tampa Java User Group. He wears many hats, including IT business owner, ex-FAANG engineer, and Board of Director MATA.
Dakshesh Kaki will provide the Gen Alpha perspective. He’s a TED Talk speaker, multiple FBLA award winner recognized by the CEO of Publix, and he’ll bring his generational lens to the future of work.
Your Truly will be the Gen X representative.
Each of us has their own take and tactics for the era of AI. Come watch this online show and learn!
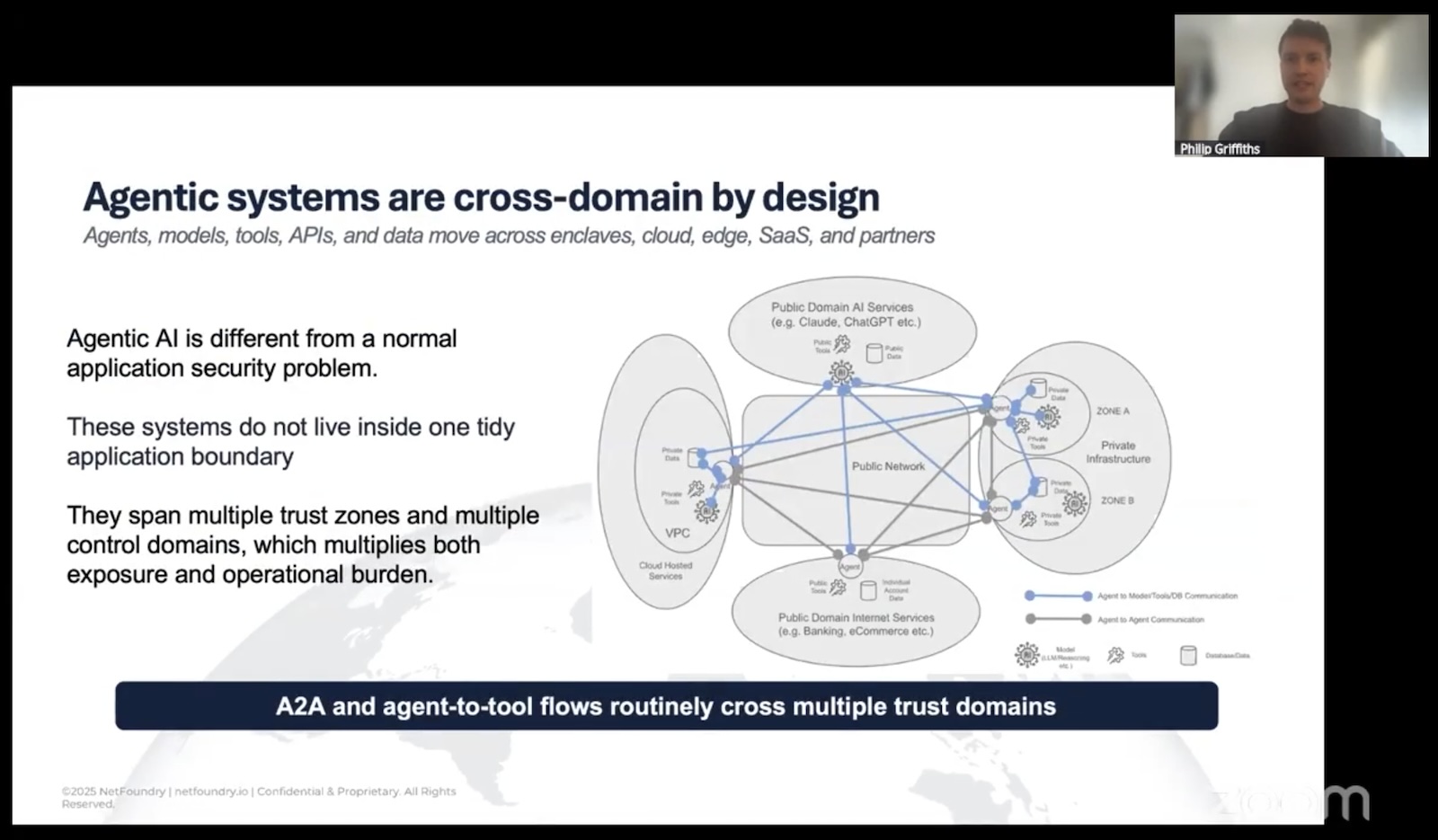
If you’ve been building anything with agents in the past year, you already know the shape of the problem even if you haven’t named it: you’ve got a model in one cloud, a vector store in another, a tool server somewhere on-prem, an MCP gateway facing the public internet, and a handful of A2A flows stitching the whole thing together. It works. Better than that, it’s exciting!
Let me say this as someone who’s spent a few years in cybersecurity and the last couple of weeks elbow-deep in OpenZiti: the AI systems that we’re implementing are built on a network model that was designed before any of this stuff existed, and that network model hasn’t kept up with what we’re doing today.
The core argument that Philip makes in his presentation is one I think every developer working on agentic systems needs to internalize, regardless of what they’re shipping on top of:
The traditional internet model lets you connect first and authenticate second. Agentic AI breaks that model so badly that we can’t pretend anymore.
Let me walk through why.
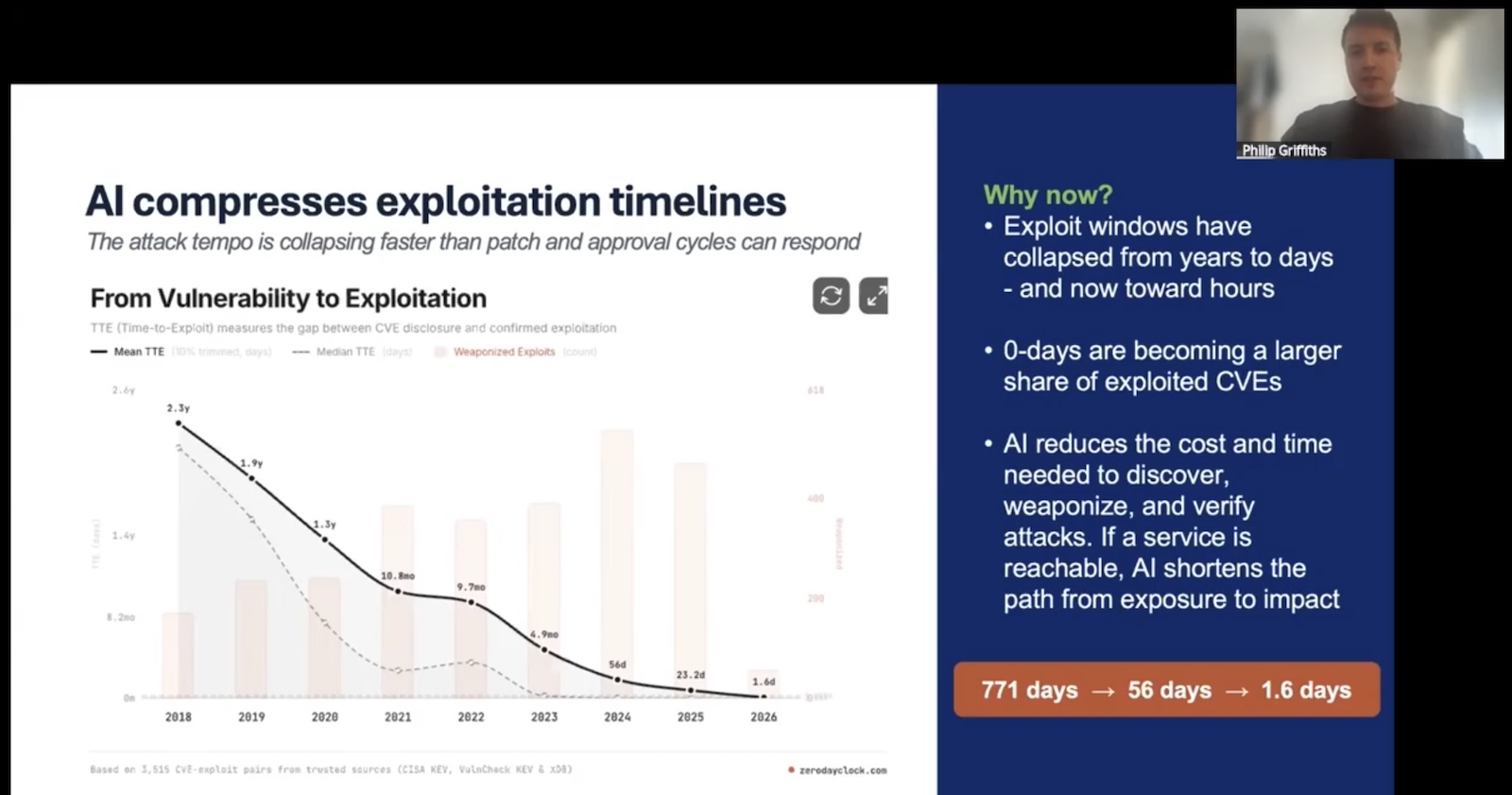
The exploit window has collapsed, and AI is the reason
Tap to view at full size
Philip opened with this knowledge bomb: the median time-to-exploit for newly disclosed vulnerabilities has dropped from days to hours.
AI has joined the Red Team. There’s AI-assisted reconnaissance, AI-assisted fuzzing, AI-assisted exploit synthesis, and more. Every part of the attacker’s pipeline is getting the same productivity boost the rest of us are getting from Copilot and Claude. The asymmetry is brutal. Defenders have to be right about every service they expose, while attackers only have to be right about one.
The LiteLLM supply-chain incident is a useful recent example. An exploit got injected upstream, and because the compromised library ran in environments where it could see them, attackers walked off with SSH keys, Kubernetes tokens, cloud credentials, and the rest of the usual environment-variable buffet. None of that would’ve happened if the service running LiteLLM wasn’t reachable from the place the attacker was sitting. Reachability was the precondition for everything else that went wrong.
In most “AI security” conversations, the talk is about the model: prompt injection, jailbreaks, output filtering, runtime guardrails, and so on. These issues matter, but there’s a much more “boring” question that’s worth asking…
Can the attacker even get a packet to your service in the first place?
If the answer is “yes”, all the model-layer controls in the world are working with their hands tied.
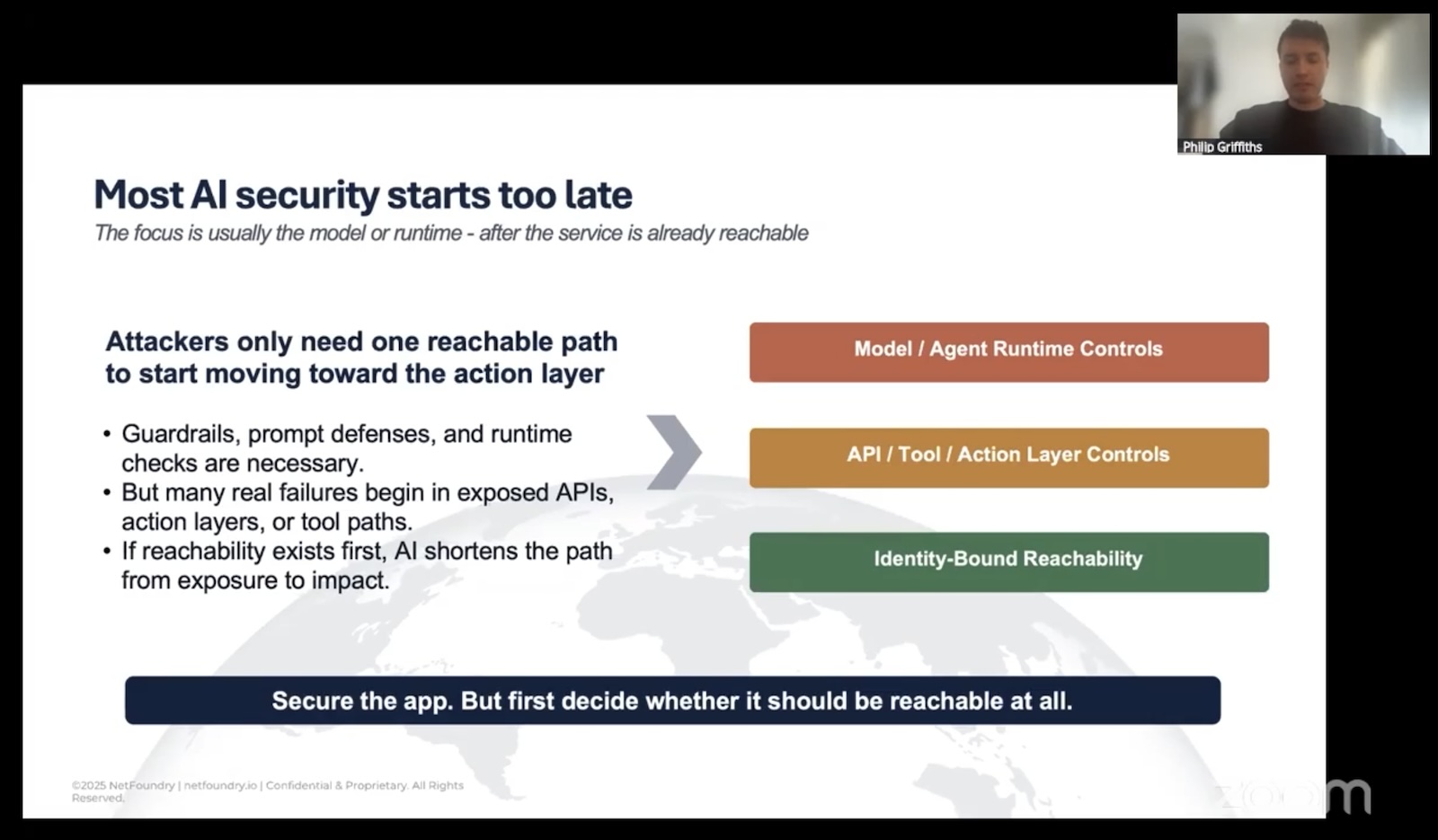
Reachability is the problem
Here’s the structural issue Philip kept circling back to, and it’s worth stating plainly because we’ve all just internalized it as how computers work:
The traditional networking model allows connectivity before authentication.
In your standard server application, you open a port. Clients, including ones that have no business knowing the server exists, sends SYN. The server completes the handshake, and then it asks the client “Who are you?”
By the time a malicious client is answering that question, the people behind it have already fingerprinted your TLS stack, learned your server software, probed for known CVEs, and maybe even identified an exploit they’d like to try.
This is fine for, say, a public web server that genuinely wants to be discovered by anyone. It is wildly inappropriate for an internal MCP gateway, an LLM endpoint scoped to a specific agent, or an A2A flow between two services that should have no business talking to anyone but each other.
There’s a reason bouncers check for ID while you’re still outside the nighclub.
Philip’s metaphor for this is…Hogwarts. Because of course it is.
Imagine if any random Muggle could walk up to Platform 9¾, see the magical world clearly visible behind a flimsy enchantment, and start poking at the bricks to figure out which sequence opens the wall. The whole point of the wizarding world’s security model is that Muggles don’t even know it’s there. Reachability is the threat. Once something is known to exist, it’s only a matter of time before somebody works out how to get in.
Most of our infrastructure today is like Hogwarts with a “Muggles Keep Out” sign on the gate. Everyone can see it. Everyone can probe it. We’re hoping the lock holds.
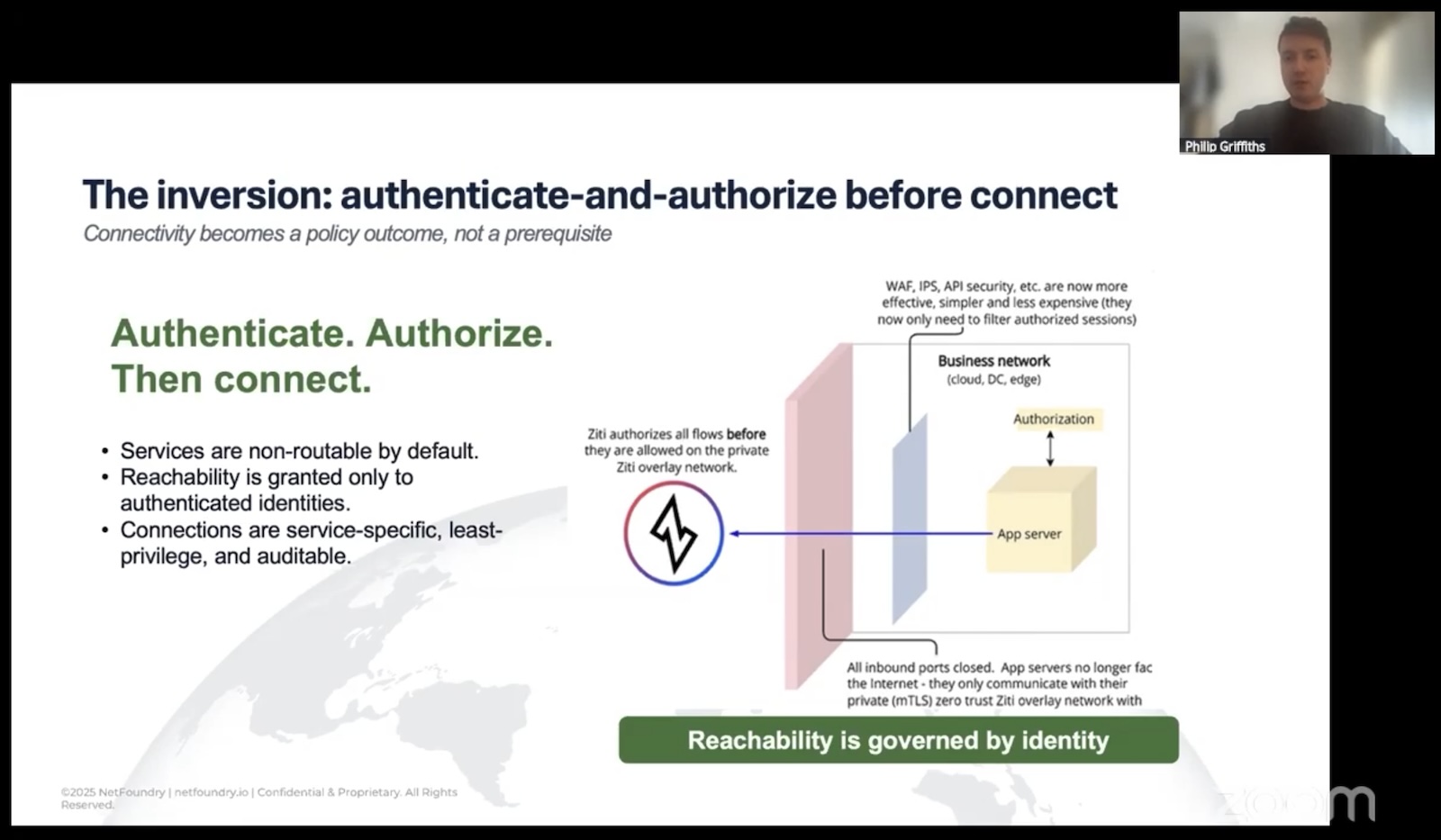
The identity-first approach
Tap to view at ffull size.
The inversion Philip proposes is something that NetFoundry’s OpenZiti project actually implements. It’s straightforward to describe and surprisingly hard to undo once you’ve seen it:
Strong cryptographic identity comes first. Every agent, every service, every endpoint gets a unique, attestable identity. Not a shared secret. Not a long-lived token someone copy-pasted into an env. An actual cryptographic identity tied to the workload.
Authentication and authorization happen before any data plane exists. No TCP handshake. No UDP packet. No DNS resolution that even confirms the service is real. If you don’t have a valid identity for this specific service under the current policy, there is nothing on the network for you to interact with.
Reachability is granted, scoped, and revocable. A policy says that identity X can talk to service Y for purpose Z. Change the policy, change the reachability. No firewall ticket. No VLAN reshuffle. No RMF package update.
Here’s the phrase that Philip used:
Connectivity should be an outcome of policy.
It shouldn’t be a prerequisite. That’s the difference:
In the traditional model, the network is a thing you build first, and then layer controls on top of it.
In the identity-first model, the network only exists between identities that have been explicitly authorized to see each other. Everything else is dark.
Tap to view at full size.
For agentic systems specifically, this matters because the topology is insanely fan-out. An agent may need to call three LLMs, four tool servers, two vector stores, and a partner organization’s API in a single workflow. Each of those is a trust boundary:
In the traditional model, every one of those flows is a potential firewall rule, a potential exposed endpoint, a potential lateral-movement path if something upstream gets popped.
In the identity-first model, each flow is a policy, and only the policy-permitted flows have any network presence at all.
The developer-velocity argument
Sure, the security argument is the headline, but if you’ve ever worked anywhere with a serious change-management process, the velocity argument might land harder.
Philip mentioned someone he’d recently spoken with who was building a new service. The platform supported outbound 443. The service needed thirty different ports. Each port change was a firewall ticket. Each ticket was an RMF update. The math on that timeline is grim, and it’s grim in commercial environments too. Anyone who’s tried to get a new outbound rule through a Fortune 500 change board has stories.
In a network where reachability is governed by policy on top of identity rather than by plumbing at OSI levels 3 and 4, that whole category of friction collapses. You’re not asking the network team to change the network. You’re updating a policy that says “this identity can now reach this service.” The underlay (your VLANs, your security groups, your jump hosts) doesn’t have to know or care.
Oh, and in case you don’t remember your OSI levels, here they are, illustrated with cats:
(Layers 3 and 4 are the network and transport layers.)
The downstream effects compound:
Telemetry gets quieter. When the only traffic that exists on a path is authenticated, authorized traffic, your SOC stops drowning in scan noise from the open internet. The signal-to-noise ratio on alerts goes way up.
Credentials simplify. No more shared service tokens that everybody on the team has a copy of. Identity is per-workload, scoped, and revocable.
The underlay becomes boring (and in security, boring is good). You can run the same workload across satcom, LTE, hotel Wi-Fi, and a hyperscaler VPC, and the security posture doesn’t change. The overlay handles it.
That last point matters more than it sounds for AI work specifically. Agents don’t sit in one tidy network segment. They reach across clouds, across organizations, across SaaS boundaries. Trying to enforce zero trust by keeping all that traffic inside a controlled underlay is a losing battle. Enforcing it at the identity layer means the underlay can be anything.
Where’s this going for agents?
Tap to view at full size
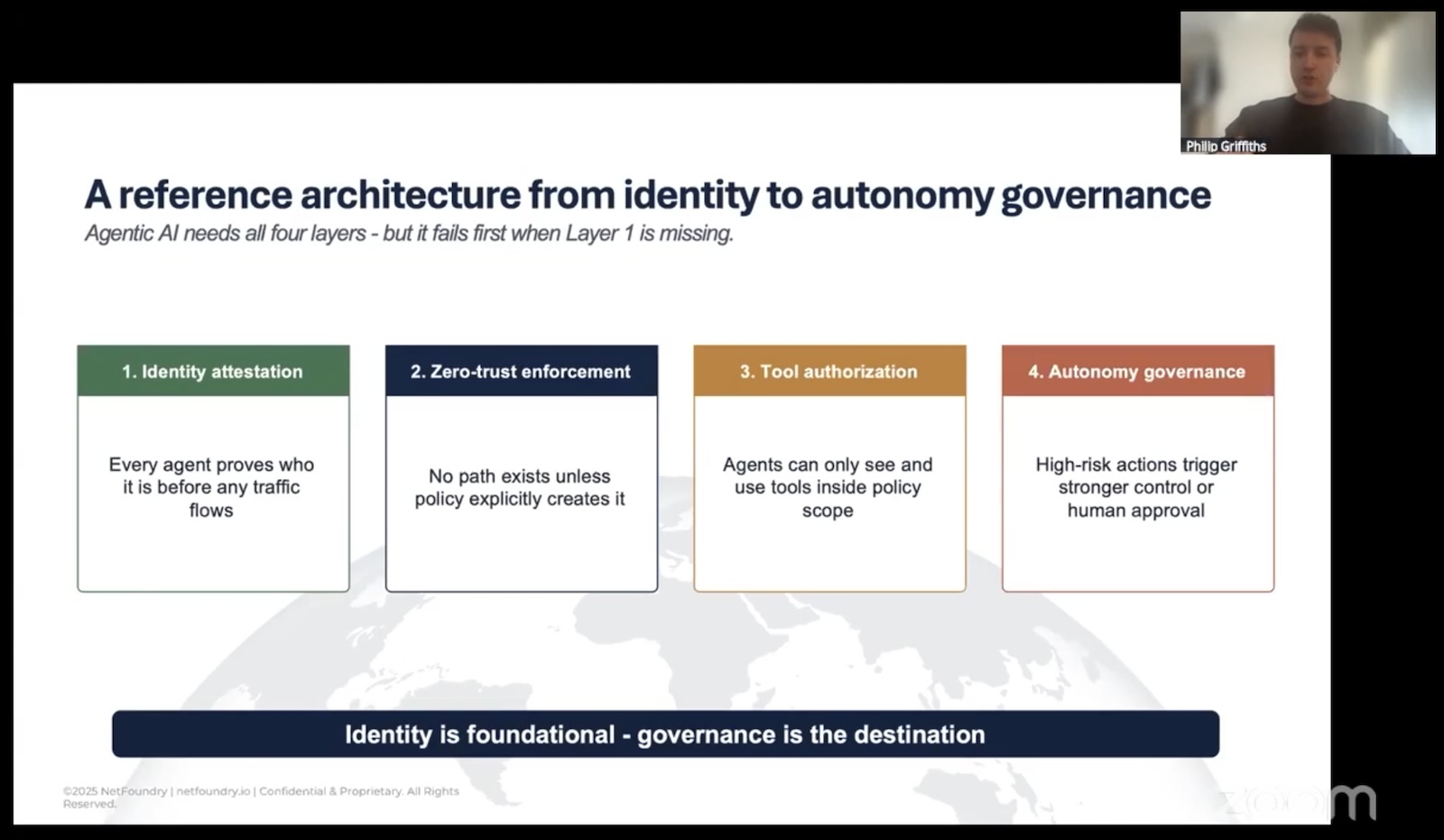
In his talk, Philip mentioned Cloud Security Alliance work, building a reference architecture for agentic systems on top of identity-first connectivity. It’s taking on this shape:
Foundation: cryptographic identity and attestation. Every agent proves what it is before any path exists.
Reachability: policy-driven, identity-scoped, no ambient network presence.
Authorization: agents see only the tools, models, and data their policy permits. No tool discovery for things they’re not allowed to touch.
Governance: human-in-the-loop for high-risk actions, audit trails tied to the cryptographic identity that took the action.
The thing I like about this stack is that the Foundation layer fixes the boring-but-fatal problem (reachability), which lets the upper layers actually do their jobs without being constantly undermined from below. You can have the world’s best prompt-injection defenses, and they don’t help you if your tool server got pwned because somebody port-scanned it from the open internet.
What you should take away if you’re a developer
It’s the middle of my third week at NetFoundry, and I’m still in the “drinking from the firehose” phase, where I’m interalizing these things:
If your threat model says “we’ll catch them at the application layer,” update your threat model. The exploit window is too short for that to be the only defense.
“Is this service reachable from where the attacker is sitting?” is the first question, not the last. If the answer can be “no,” make it “no.”
Identity-first is not a product category you buy. It’s a property your architecture either has or doesn’t. You can get there with OpenZiti, with various commercial overlays, with SPIFFE/SPIRE for the identity piece, with combinations. The label matters less than the property. (But hey, I’d love it if you went with OpenZiti, and double if you tell NetFoundry you heard about it from me!)
The biggest unlock isn’t security, it’s that you stop spending your week filing firewall tickets.
Philip closed with a line that I think is the right one to leave on, paraphrased: any sufficiently advanced security model looks like magic. In this context, magic means the thing you’re trying to attack isn’t there. That’s the bar. Not “well-defended.” Not “hardened.” Not visible at all unless you’ve already proven who you are.
For agentic AI, where the speed of attack and the fan-out of the topology are both moving in directions that make traditional networking less viable every month, that bar is starting to look less like a nice-to-have and more like the only model that actually scales.
If you want to dig in: the OpenZiti project is open source and a reasonable place to get hands-on with what identity-first overlay networking actually looks like in practice.
Just days before the trial started, Elon Musk tried to settle his lawsuit, which alleges that under Sam Altman’s direction, OpenAI abandoned its mission to serve as a nonprofit making AI to benefit humanity.
According to a Sunday court filing from OpenAI, Musk messaged OpenAI President Greg Brockman two days ahead of the trial to “gauge interest” in a possible settlement. Brockman promptly responded, suggesting that “both sides” drop their claims. But Musk refused, then appeared to grow threatening enough that the court may allow Brockman to testify on the message as evidence supposedly revealing Musk’s true motives for pursuing the litigation.
“By the end of this week, you and Sam will be the most hated men in America,” Musk responded to Brockman’s suggestion that all claims be dropped. “If you insist, so it will be.”
OpenAI clearly did not accept the settlement terms, as the trial started last week with Musk as the first witness. On the stand, Musk stumbled several times, perhaps weakening his case by making concessions, growing hot-tempered, backing off claims that AI risks may quickly become existential, and admitting his ignorance when it comes to AI safety at his own company, xAI.
In short, it’s classic Muskrat moves: make threats, dilute said threats, get huffy, admit ignorance in a field where he claims expertise, repeat.