Just over two months after my announcement that I was doing developer relations for HP’s ZGX Nano AI workstation — an NVIDIA-powered, book-sized desktop computer specifically made for AI application development and edge computing — HP ended the Kforce contract for the ZGX Nano program, so my last day is Friday.
Just over two months after my announcement that I was doing developer relations for HP’s ZGX Nano AI workstation — an NVIDIA-powered, book-sized desktop computer specifically made for AI application development and edge computing — HP ended the Kforce contract for the ZGX Nano program, so my last day is Friday.
In my all-too-brief time working with HP, I got a lot done, including…
I landed the ZGX Nano appearance on Intelligent Machines
On the very day I announced that I was doing developer relations for the ZGX Nano, I got an email that began with this paragraph:
I’m Anthony, a producer with the TWiT.tv network. Jeff Jarvis mentioned you’re “a cool dude” from the early blogging days (and apparently serenaded some Bloggercons?), but more importantly, we saw you just started doing developer relations for HP’s ZGX Nano. We’d love to have you on our podcast Intelligent Machines to discuss this shift toward local AI computing.
First of all: Thanks, Jeff! I owe you one.
Second: I didn’t pitch TWiT. TWiT pitched me, as soon as they found out! This wasn’t the outcome of HP’s product marketing department contacting media outlets. Instead, it’s because Jeff knows me, and he knew I was the right person to explain this new AI hardware to their audience:
I generated earned media for HP without a single pitch, press release, or PR agency. My personal brand amplified HP’s brand, and maybe it can amplify your company’s brand too!
And finally: I’m just great at explaining complex technical topics in a way that people can understand. Don’t take my word for it; take Leo Laporte’s:
In case you need some stats:
- TWiT Network (home of Intelligent Machines): 25+ million downloads annually
- Cost of equivalent advertising slot: $double digit thousands
- Time from my hire to major media appearance: 8 weeks
- Number of PR pitches sent: 0
- Value of authentic relationships: Priceless
I built page-one visibility for a brand-new product —organically
Do a Google search on the term zgx nano (without the quotes) and while you might see slightly different results from mine, you should find that this blog, Global Nerdy, is on the first page of results:
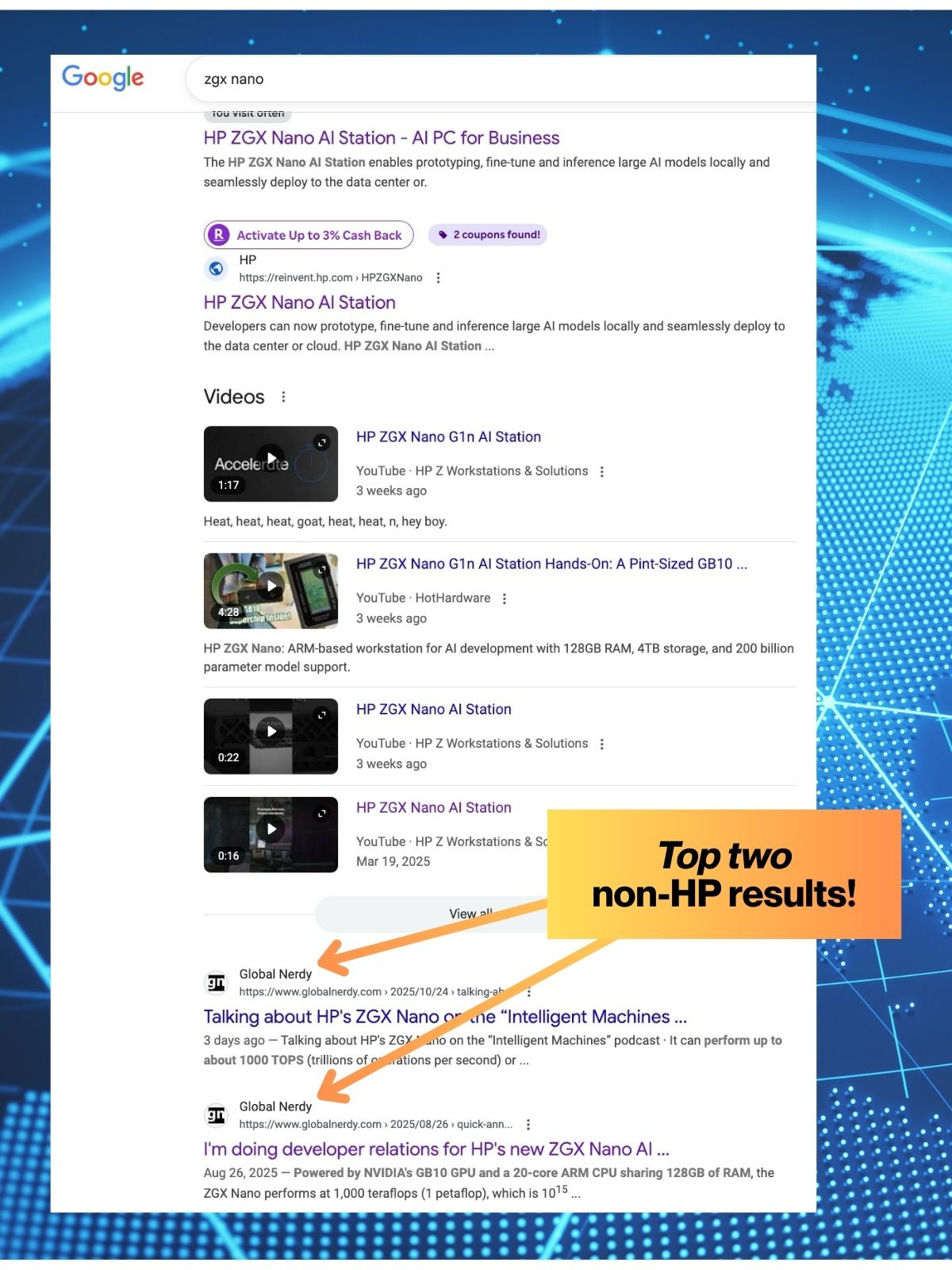
The screenshot above was taken on the evening of Monday, October 27, and two of the articles on this blog are the first two search results after HP.
My content gets found. Within 8 weeks of starting work with HP, my coverage of the ZGX Nano achieved first-page Google ranking, competing directly with HP’s official pages and major tech publications. This organic reach is what modern developer relations looks like: authentic content that both developers and search algorithms trust.
With me, you’re not just getting a developer advocate, but someone with a tech blog going back nearly two decades and with the domain authority to take on with Fortune 500 companies on Google. My Global Nerdy posts about ZGX Nano rank on page one because Google trusts content I’ve been building since 2006.
I enabled the Sales team to go from zero to hero

On day one, I was given two priorities:
- First, provide enablement for the Sales team and give them the knowledge and selling points they need to be effective when talking to customers about the ZGX Nano.
- Support developers who were interested in the ZGX Nano, or even just AI application development. Unfortunately, I’m not going to get to execute this phase.
But I got pretty far with that first phase! In less than eight weeks, I built a sales enablement foundation for a brand-new AI workstation with scant documentation. I created 50+ pages of technical documentation that gave HP’s global sales force what they needed to sell a new product in a new category.
Some of my big quantifiable achievements in sales enablement:
- 25+ technical objections anticipated and addressed
- Created comprehensive FAQ covering everything from architecture to ROI calculations
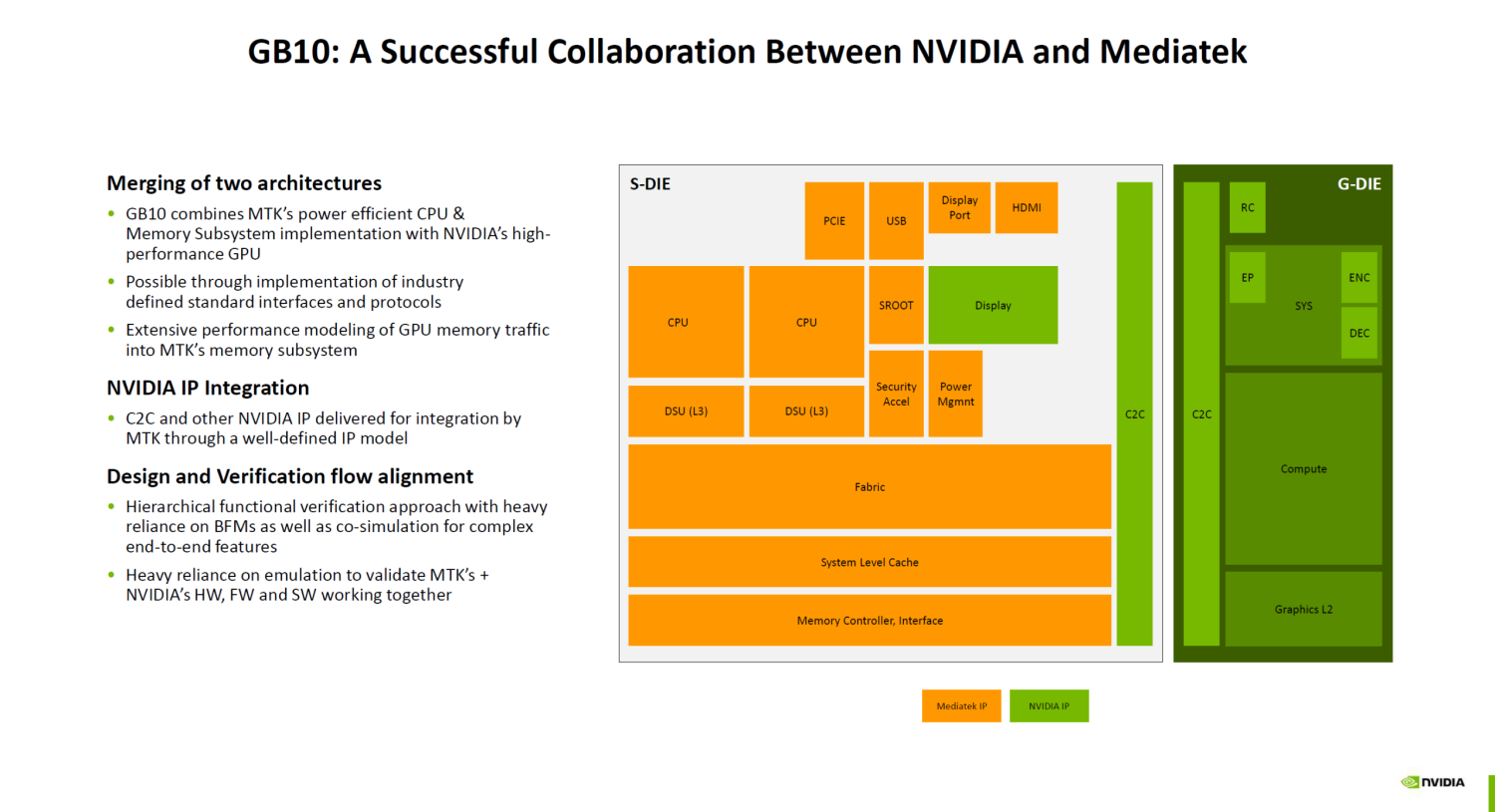
- Translated GB10 superchip complexity into sales-friendly language
- Provided competitive differentiation against NVIDIA DGX Spark, Dell, and Lenovo
- 12 industry verticals mapped with 60+ business impact scenarios”
- Developed go-to-market strategy for each vertical (healthcare to gaming)
- Created specific ROI talking points for each industry
- Identified 5 business impacts per vertical = 60 total selling points
- Turned “It’s just another GB10 machine” into “Here’s why HP wins”
- Differentiated commodity hardware through software story (ZGX Toolkit)
- Created objection handling that transforms skepticism into sales
- Armed sales with “Why HP and not NVIDIA direct””messaging
I’m available starting next week!
All told, it was 2 months, 1 podcast…and ZERO regrets. I enjoyed the work, and I’m grateful to have been selected to be the developer spokesmodel for an amazing AI computer.
I don’t think of this as a termination. It was a high-intensity proof-of-concept for my ability to help launch a new device with little guidance (in fact, the manager who hired me moved to another company on my first week). They asked; I delivered. Now, I’m looking for the next impossible mission.
As I wrote at the start of this article, my last day is on Friday — yes, I wrap up on Halloween — and as of Monday next week, I’m available!
I’m now looking for my next Developer Advocate role. Who needs someone who can…
- Land major podcast appearances on Day One?
- Has enough SEO know-how and influence to get you to Page One?
- Can enable your sales and marketing teams with technical material, explained in a non-techie-friendly way?
If you’re looking for such a person, either on a full-time or consulting basis, set up an appointment with me on my calendar.
Let’s talk!