Yesterday, Anitra and I were flying back to Tampa from New York’s LaGuardia Airport, and I noticed that most of the ads flashing on the billboard screen overlooking our departure lounge were for AI companies or products.
There were two different ads for Codex (one pictured above, one below)…
I don’t think I’ve ever put in as much work into a talk as I have for my upcoming talk at DevRelCon NYC 2026 (that’s “DevRelCon” as in “developer relations conference”), The Market is Trying to Tell You Something. It’s a lightning talk meant to fill up no more that 10 minutes including Q&A and the transition between talks, but the ratio of hours-of-prep to minutes-of-actual-talk is massive.
What is DevRelCon?
DevRelCon NYC 2026 takes place July 22 – 23 at Industry City, Brooklyn, New York.
DevRelCon is the long-running conference series for people who do developer relations/developer advocacy, which once upon a time also went by “developer evangelism”. This line of work involves helping software developers discover, understand, and actually stick with a product, whether that’s through a combination documentation, demos, community, and developer experience.
DevRelCon was created by the developer relations agency Hoopy and began in London in 2015. It’s since grown into an international series of conferences with editions in London, Prague, San Francisco, Tokyo, China, Latin America, and online. I’m speaking at the New York 2026 edition, which is organized by Mike Swift and Major League Hacking, the global community for early-career developers and software creators.
DevRelCon is positioned as the premier conference for anyone working to grow developer adoption, spanning developer relations, developer experience, product marketing, platform product management, and everyone’s favorite three-letter acronym, GTM. In other words, it’s a room full of exactly the people my talk is about, which is either the best or the most terrifying possible audience for a talk on what the DevRel job market is really telling us. (Probably both.)
My business card. Click to see at full size.
DevRelCon NYC 2026 will take place July 22 – 23 at Industry City, Brooklyn, New York. It is the first conference I’m speaking at as an official representative of NetFoundry.
What’s The Market is Trying to Tell You Something all about?
Join me at the DevRelCon afterparty and I’ll tell you the Christmas Eve “homework assignment” story over a beer.
The talk is based on my experiences in 2025, when I did something I don’t recommend as a hobby but made for a great natural experiment: I let the DevRel job market interview me a couple dozen times. That’s my dressed-up way of saying “I was looking for a job”.
I went through recruiter screens, faced hiring panels, did take-home demos (one on Christmas Eve, based on the urging of a recruiter), and went through final rounds — across AI-native startups, enterprise infrastructure shops, and everything in between.
Somewhere around the tenth interview, I stopped just trying to get hired and started noticing a pattern:
Job descriptions had quietly rewritten themselves.
Interviews are testing for things the job description never mentions.
And “DevRel ROI”, which used to be a phrase that was thrown in with an accompanying hand-wave, now means something specific that it didn’t mean in the zero-interest 2010s or the Great Resignation hiring frenzy of a couple years ago.
My talk is my attempt to decode those signals: what the market is actually screening for, how what it says and what it wants are often different, and what any of us (whether you’re job-hunting, hiring, or just trying to make sure your role survives its next budget review) should do about it. It’s eight minutes. There will be an accordion. That’s all I’ll say for now.
DevRelCon NYC is the developer relations conference for North America, it’s happening in Brooklyn on July 22 and 23, and I’m a speaker!
Here’s a quick writeup of my talk, as it appears on the schedule:
The Market is Trying to Tell You Something
The DevRel job market has been sending signals for two years. Most of us have been too busy surviving it to read them. After 15+ years in Developer Relations and a recent job search that took me across a couple dozen companies, I came away with both a new role and something just as valuable: a pattern.
Job descriptions have quietly shifted. Hiring panels are asking different questions. “DevRel ROI” means something specific now that it didn’t mean in the zero-interest 2010s or the Great Resignation era of a couple of years ago. The skills companies say they want versus the skills that actually get you hired don’t look like they come from the same list.
This talk is an honest, experience-based, practitioner-level read of what the market is telling us about where DevRel is headed. It doesn’t have any LinkedIn takes or recycled frameworks; just patterns from the front lines, with implications for how you position yourself, make the case for your team, and think about the next few years of your career.
In addition to giving a talk, I’ll be there to learn as well as represent NetFoundry.
DevRelCon typically brings in about 300 attendees, mostly professionals from developer relations, developer experience, and developer community-building roles to discuss industry trends, methodology, and as of late, AI integration, as well as to do some networking (a key part of DevRel).
DevRelCon was created by the developer relations agency Hoopy and began in London in 2015. DevRelCon NYC is organized by Mike Swiftand Major League Hacking, a global community for early-career developers and software creators, of which Mike is co-founder.
DevRelCon NYC takes place on Wednesday, July 22 and Thursday, July 23 at Industry City in Brooklyn, New York. I’m arriving early in the afternoon of Tuesday, July 21 and will be attending some of the pre-DevRelCon festivities.
Last year’s DevRelCon NYC talks
Here’s the set of DevRelCon NYC 2025 talks that have been posted to YouTube. I’m using these as a guide for my own talk (as well as for ideas for my own developer relations work at NetFoundry), and you might find these helpful for your own work, or to help you decide if DevRelCon NYC 2026 is for you!
As usual, we’ll talk about the week’s tech events and what they’ve been up to recently, and I’ll probably talk about joining NetFoundry and working as a developer advocate promoting OpenZiti and the AI platform that builds on it.
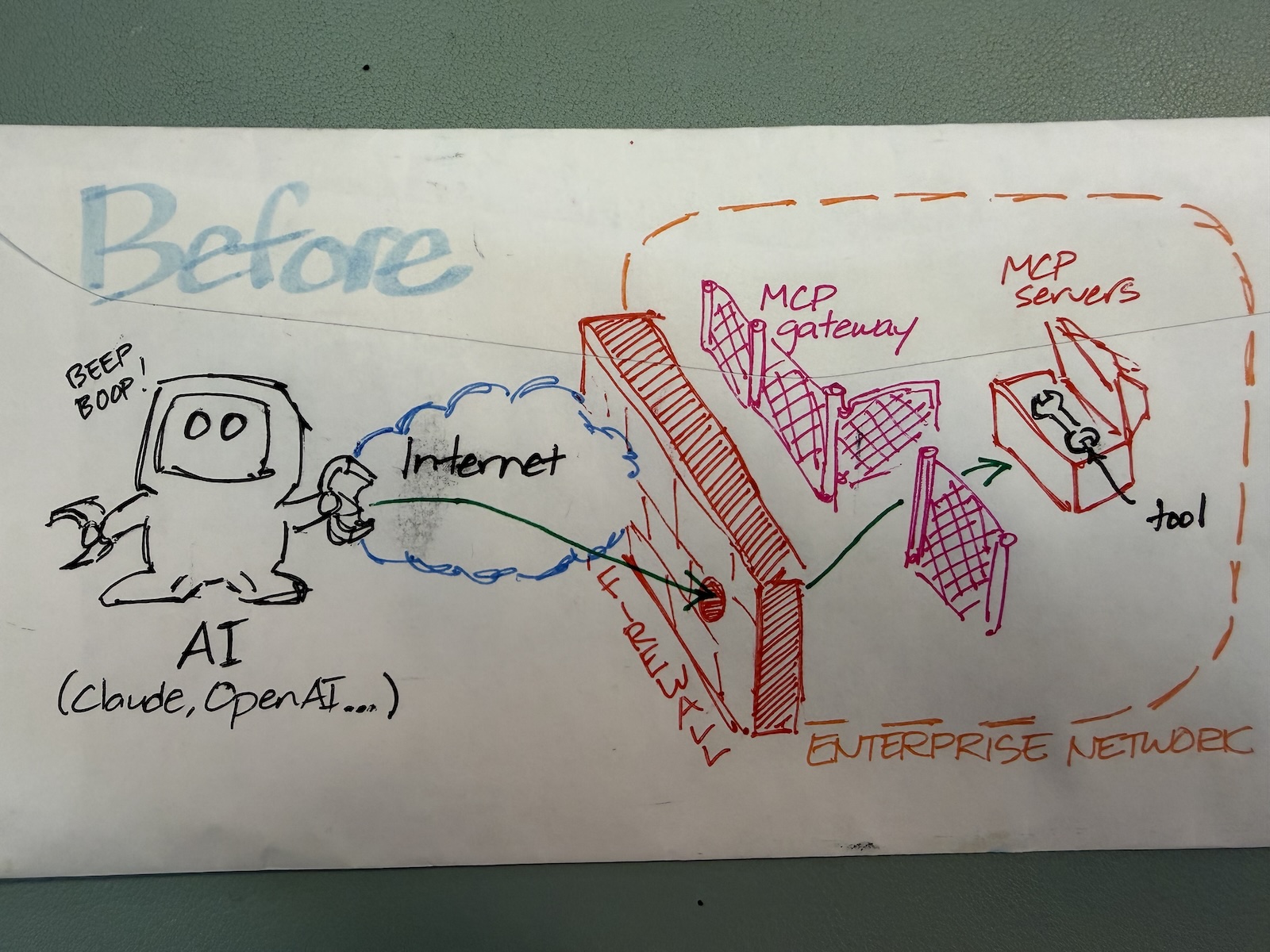
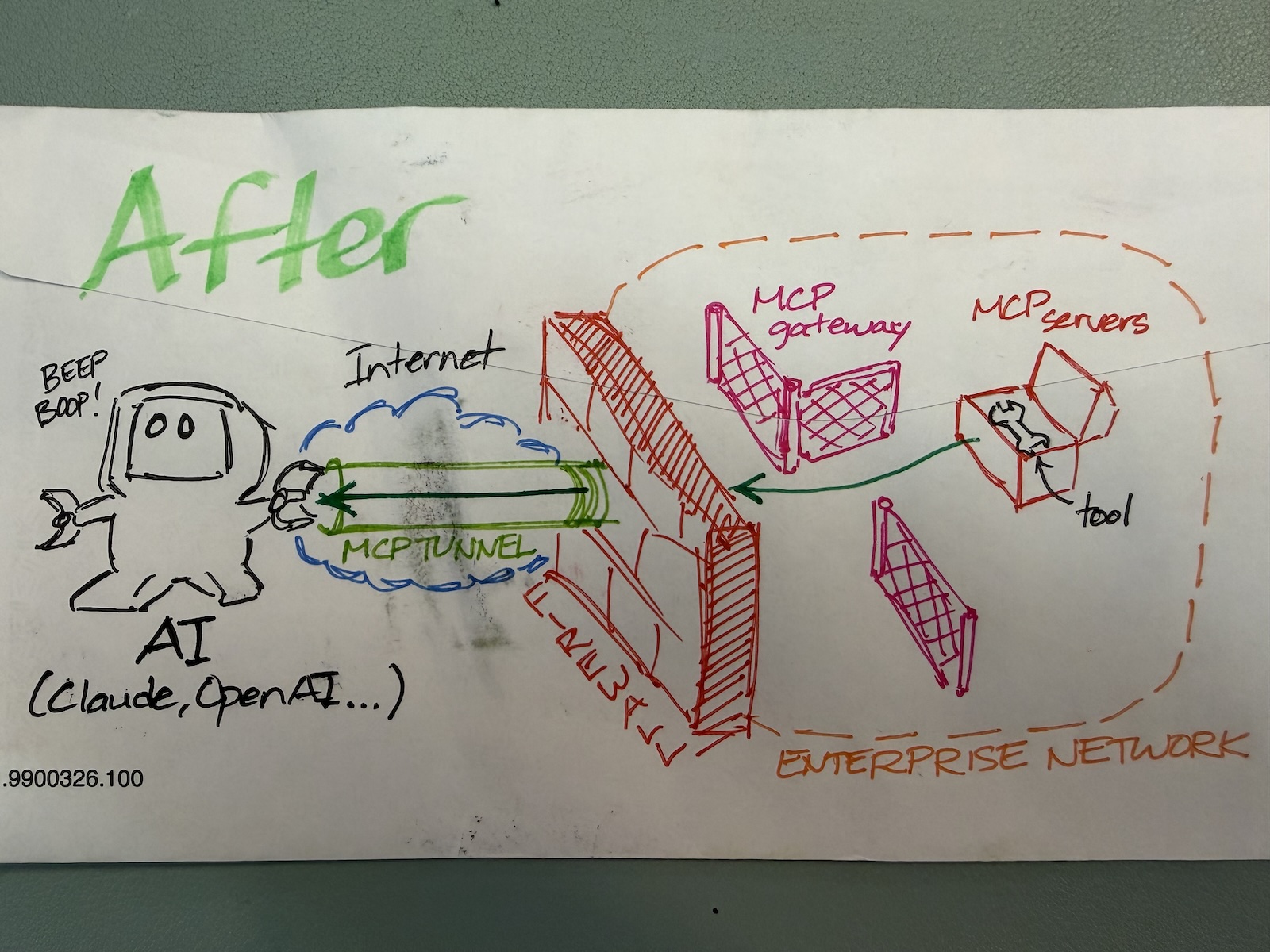
“Back of the envelope” is a time-honored tech tradition where someone does a quick calculation, works out a plan, or illustrates a concept on the nearest convenient piece of paper, which was often the back of a paper envelope.
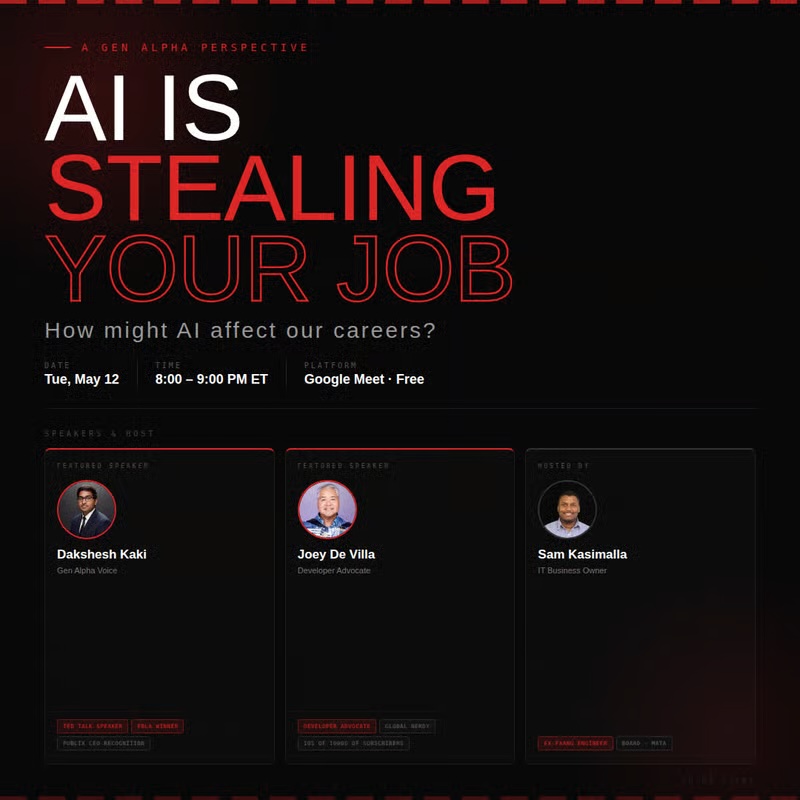
I don’t need to tell you that AI’s already replacing jobs (or at least being used as an excuse), reshaping industries, and rewriting the rules of the workforce and the ways we work. Wouldn’t it be nice to get some perspective?
Join us this Tuesday! On the panel will be:
Sam Kasimalla as the host. You’ll know him from all sorts of local events, including Tampa Java User Group. He wears many hats, including IT business owner, ex-FAANG engineer, and Board of Director MATA.
Dakshesh Kaki will provide the Gen Alpha perspective. He’s a TED Talk speaker, multiple FBLA award winner recognized by the CEO of Publix, and he’ll bring his generational lens to the future of work.
Your Truly will be the Gen X representative.
Each of us has their own take and tactics for the era of AI. Come watch this online show and learn!