Is data science still among the sexiest jobs of the 21st century?

It was in a 2012 Harvard Business Review article that data scientist was declared “the sexiest job of the 21st century”. Is it still true six years later?
I’ll spare you the torment and give you the answer, which (naturally) appears at the end of the article:
The role of data scientists is and will remain a sexy profession for some time, partly due to its relative exclusivity, and the field of data science itself will no doubt remain an exciting space.
You may find the middle of the article a little more useful, as it lists qualities of good data scientists:
A good data scientist should be:
- Adaptable: Data scientists must be willing to constantly upskill themselves to master advanced machine learning skills such as deep learning. While technical skills are fundamental for data scientists, it’s crucial for them to master communication skills too so they can easily interact with domain experts or business developers. Data scientists will need to develop a better understanding of the overarching business strategy and business challenges in real-world scenarios to create solutions for real problems.
- Statistics at the heart: Data scientists must have quantitative capabilities to figure out multifaceted trends within a data set that may entail more than one million rows.
- Detail-oriented: Data often have errors and discrepancies, and data scientists must identify and correct incomplete, incorrect or inaccurate data. It’s critical that data are clean, high-quality and unbiased to ensure the best output upon which to make business decisions.
- Good programming skills: Programming skills, together with statistics, are critical. For statistical analysis to happen, data scientists need to know programming languages (such as Java, SQL, and Python) to break down the data set in more digestible formats.
- Business knowledge: While it is important for data scientists to be technically capable, they must also be business savvy and understand the organisation’s business goals and objectives, so they can analyse the data to support business success.
The most in-demand skills for data scientists
Here are the two key graphs from the article:
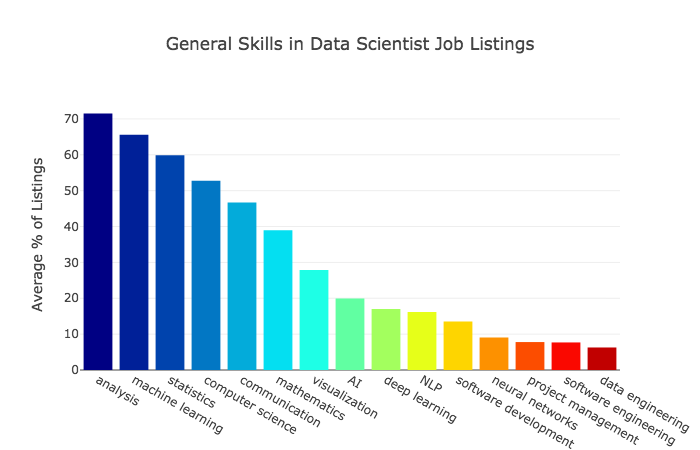
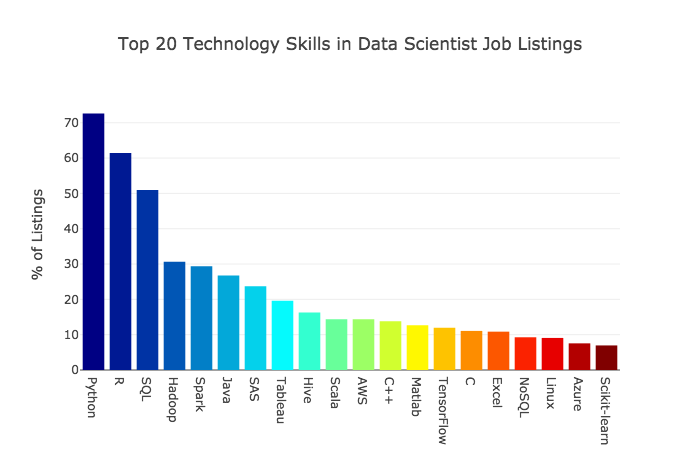
From the end of the article:
Based on the results of these analyses, here are some general recommendations for current and aspiring data scientists concerned with making themselves widely marketable.
- Demonstrate you can do data analysis and focus on becoming really skilled at machine learning.
- Invest in your communication skills. I recommend reading the book Made to Stick to help your ideas have more impact. Also check out the Hemmingway Editor app to improve the clarity of your writing.
- Master a deep learning framework. Being proficient with a deep learning framework is a larger and larger part of being proficient with machine learning. For a comparison of deep learning frameworks in terms of usage, interest, and popularity see my article here.
- If you are choosing between learning Python and R, choose Python. If you have Python down cold, consider learning R. You’ll definitely be more marketable if you also know R.
Four Ways the Data Scientist Has Evolved in the 21st Century

These four ways are:
1. Data science is more applied than ever. What can be built and fit over a real-life scenario has the dreadful requirement of mattering. Modeling for modeling sake is no longer a thing, and best-fit diagnostics are less important than best-fit for the situation. If a model goes unused, it serves no purpose. We can no longer tolerate or afford the luxury of building models purely for R&D purposes without consideration of utilization.
2. The skill of computer use seems to have taken over the knowledge of applied statistics. Understanding the interior workings of the black box has become less important, unless you are the creator of the black box. Fewer data scientists with truly deep knowledge of statistical methods are kept in the lab creating the black boxes that hopefully get integrated within tools. This is somewhat frustrating for long time data professionals with rigorous statistical background and understanding, but this path may be necessary to truly scale modeling efforts with the volume of data, business questions, and complexities we now must answer.
3. Data scientists are not weird anymore. We’re seen as strategic inputs to the decision-making process, and our craft is becoming much more understood. This trend is evidenced by C-level positions at large companies, vertical alignment and paths for data scientists, and inclusion at the highest levels, as well as the many academic programs and emphasis now available globally. This appreciation and positioning can sometimes make the field appealing for what seasoned data scientists might call the “wrong reasons” such as corporate fame and value. I would argue that we really want professionals in the field with a thirst for the truth – the science should be about empirically answering questions, and powered by truth-seekers at their heart.
4. Data Science is becoming more widely recognized as both art and science. Understanding the importance of the human – machine integration and complementary decision-making skills from each appears to have made its way more squarely into our field of understanding.
Statistical Significance, the Null Hypothesis and P-Values Defined & Explained in One Minute

And finally, some material that’s more than just hand-waving: a quick explanation of what the null hypothesis and p-values are, all done in a minute, courtesy of One Minute Economics:




