
By popular demand, here are the “slides” from my presentation this morning at Civo Navigate Local Tampa, Make Smarter AI Apps with RAG!

Retrieval-Augmented Generation, also known as RAG for short, is an AI technique that combines…
- A machine learning model with
- A mechnanism for retrieving additional information that the model doesn’t have
…to enhance or improve the responses generated by the model.
At this point, you’re probably thinking this:
This talk runs from 11:15 to 11:30 a.m., which is just before lunch, and I’m not at my cognitive best. Can you explain RAG in an easy-to-digest way, possibly using Star Wars characters?
I’m only too happy to oblige!
Consider the case where you ask an LLM a question that it doesn’t “know” the answer for. The exchange ends up something like this:

With retrieval-augmented generation, you improve the response by augmenting the prompt you send to the LLM with data or computation from an external source:
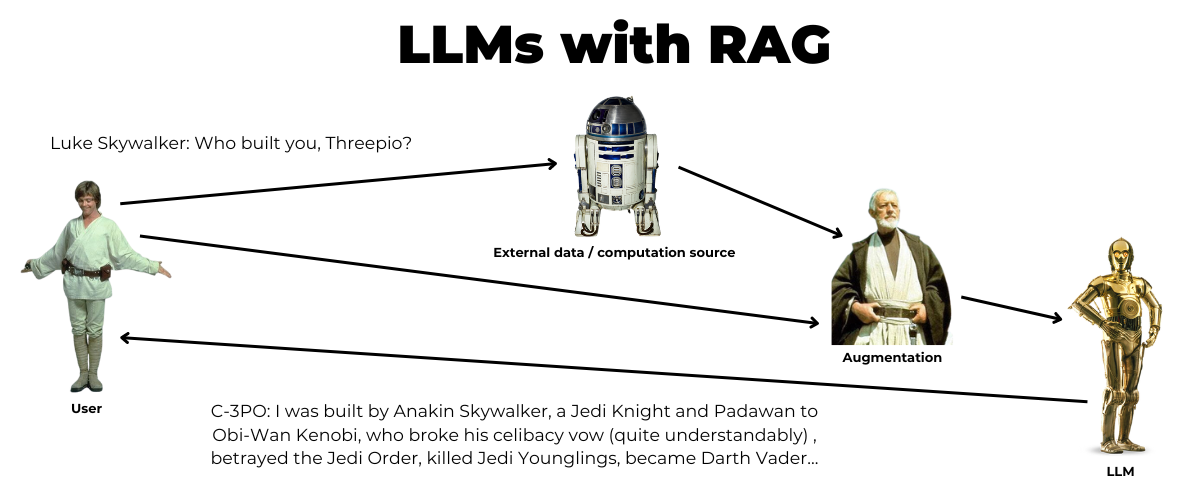
Because RAG provides additional information to the LLM, it solves two key problems:

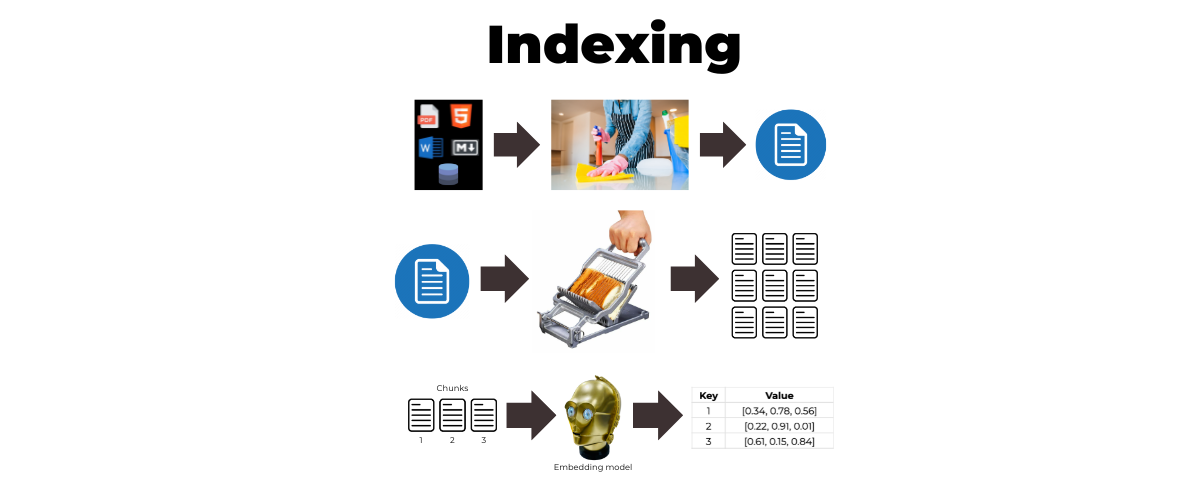
Here’s a lower-level view of RAG — it starts with the cleaning and conversion of the supplementary data:

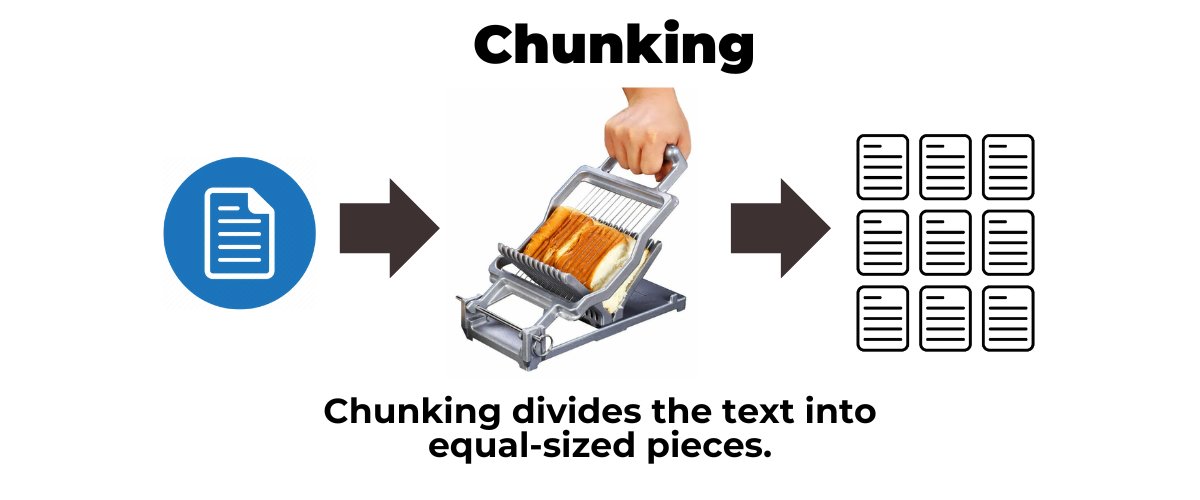
Once that supplemetary data has been cleaned and converted, the next step is to convert it into small chunks of equal size:
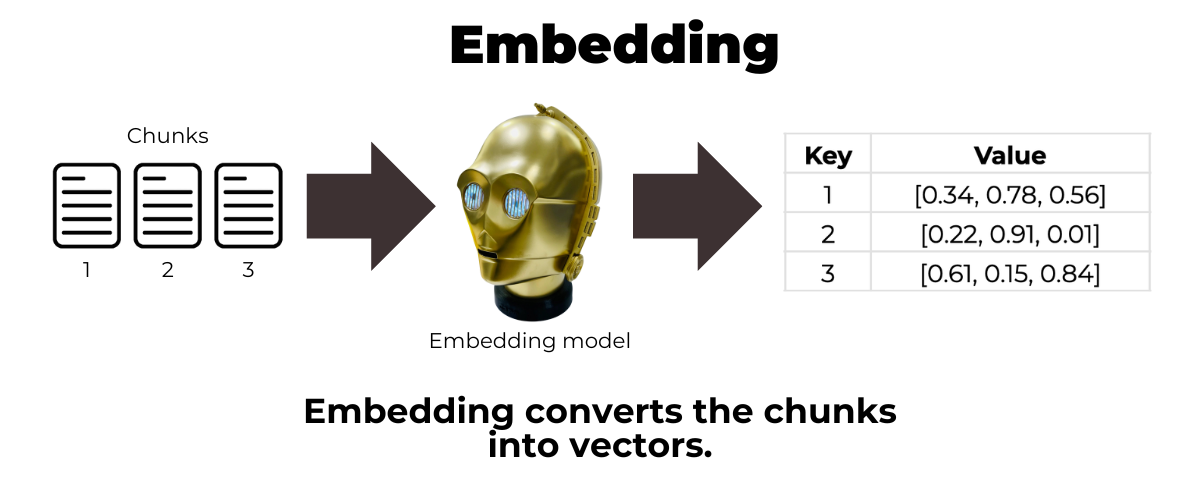
Those chunks are then converted into vectors. If you’re not really into math but into programming, think of vectors as arrays of numbers. Each of the numbers in the vector is a value between 0.0 and 1.0, and each vector typically has hundreds of elements. In a diagram below, I’ve greatly simplified the vectors so that they’re made up of only three elements:
The whole process of cleaning/converting, then chunking, then embedding is called indexing:
Now that you know what’s happening “under the hood,” let revisit the RAG diagram, but with more detail:
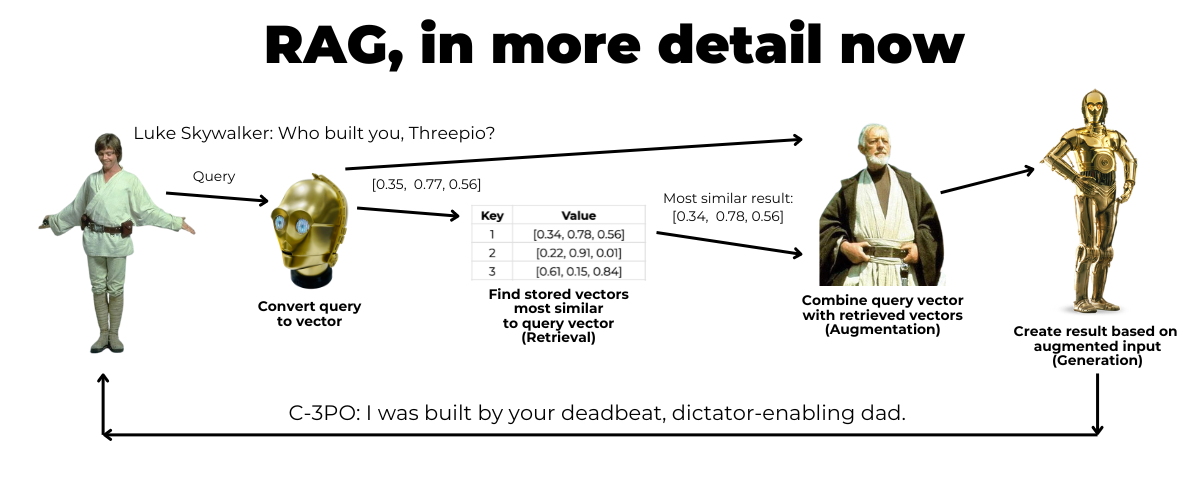
Here’s what’s happening:
- Luke asks the question: “Who built you, Threepio?” That’s the query.
- The query is converted into vectors.
- The “vectorized” query is compared against the vectors that make up the supplementary information — the vectorstore — and the system retrieves a small set of the vectors that are most similar to the query vector.
- The query vector and the supplmentary vectors from the vectorstore are combined into a prompt.
- The prompt is then sent to the LLM.
- The LLM responds to the prompt.
That was the “hand-wavey” part of my lightning talk. The rest of the talk was demonstrating a simple RAG system written in Python and running in a Jupyter Notebook. If you’re really curious and want to see the code, you can download the Jupyter Notebook here.