
Welcome to another installment of Counting Down to Seven, a series of articles about mobile app development that I’m writing as we count down the days to MIX10, when we reveal more about the up-and-coming Windows Phone 7 Series.
You’re going to have to wait a couple more weeks before I can tell you the specifics of Windows Phone 7 development. In the meantime, I thought I’d write about mobile development in general. If you’re new to mobile development, this series will be a nice overview of the field; if you’ve built apps for mobile phones before, think of it as a refresher course, but you might learn something you didn’t know before.
Mobile Design and Development, by Brian Fling
 The O’Reilly book Mobile Design and Development is a worthwhile read for anyone who’s planning to build and sell mobile applications. It’s written by Brian Fling, the owner of the “mobiledesign” mailing list (which could use a little love and attention these days), advisor to big brands getting into the mobile space and someone who (according to his author bio) has “worked with a lot of well funded companies that have failed miserably”.
The O’Reilly book Mobile Design and Development is a worthwhile read for anyone who’s planning to build and sell mobile applications. It’s written by Brian Fling, the owner of the “mobiledesign” mailing list (which could use a little love and attention these days), advisor to big brands getting into the mobile space and someone who (according to his author bio) has “worked with a lot of well funded companies that have failed miserably”.
Mobile Design and Development is probably the best general book on mobile development available right now. You’re not going to learn any specific phone’s API from this book; instead, you’ll learn about the industry, its state as of the time the book was published (August 2009) and the sort of things you should be thinking about if you’re developing mobile apps for an audience. While the ever-changing nature of the mobile world means that some of the information in the book has a “sell-by” date, many of the ideas covered in the book will be applicable for much longer.
“The 7th Mass Medium”
By happy coincidence, the version number of our soon-to-be-unleashed mobile OS, 7, keeps popping up in discussions of mobile technology.
The number 7 makes an appearance in Mobile Design and Development’s third chapter, titled Why Mobile? In it, Fling refers to mobile technology as “The 7th Mass Medium”, an term he attributes to Tomi T. Ahonen, author of the book and blog Communities Dominate Brands.
You were probably wondering what the 6 previous mass media are. In chronological order, they’re:
- Sound recordings
- Cinema
- Radio
- Television
- Internet
The interesting thing about the 7th mass medium is that it encapsulates the previous 6. Although we’re only just beginning to do so, we read, listen, watch and surf on mobile devices.
The 7 Unique Qualities of the 7th Mass Medium
 Mobile Design and Development cites an old blog entry of Ahonen’s, in which he lists 5 unique qualities of mobile as a medium. Ahonen wrote a later article, bumping that number up to 7. They’re things worth keeping in mind when you’re designing mobile apps. Depending on your point of view, some of the qualities may be good things or bad things, but no matter what you think of them, you have to account for them. They are:
Mobile Design and Development cites an old blog entry of Ahonen’s, in which he lists 5 unique qualities of mobile as a medium. Ahonen wrote a later article, bumping that number up to 7. They’re things worth keeping in mind when you’re designing mobile apps. Depending on your point of view, some of the qualities may be good things or bad things, but no matter what you think of them, you have to account for them. They are:
1. The mobile phone is the first personal mass medium.
We share books and magazines, listen to the radio and dance to DJ en masse, watch TV shows and movies with others, and many households have a computer used by more than one person. But for most people, their mobile phone is theirs and theirs alone.
Ahonen points to a 2006 survey by the advertising agencies BBDO and Proximity in which that 63% of the people surveyed wouldn’t lend their mobile phone to anyone else.
2. The mobile phone is a permanently carried medium.
According to a Morgan Stanley survey from 2007, 91% of the respondents said that they kept the phone within a meter of them day and night, even when in the bathroom or asleep. Many people use it as the 21st century equivalent of the pocket watch, and when I travel, I’ve found it to be a very reliable alarm clock. It’s the computing, communications and media device you have with you all the time.
According to BBDO/Proximity 2006 study cited in the previous point:
- People in China were choose between retrieving a forgotten wallet or phone at home; 69% chose the phone.
- Women in Japan have daytime and evening phones, in the same way they have daytime and evening handbags.
3. The mobile phone is the only always-on mass medium.
There may be times when we turn off the ringer and vibrate functions, but the only time most people turn off their mobile phones is when they’re on a plane (and if you fly often, you know that many people turn on their phones moments after the plane’s wheels touch the ground). The closest any other medium comes to always-on is the internet that subset of people who keep a computer with broadband powered up all the time, followed by falling asleep with the TV or radio on.
According to BBDO/Proximity 2006 study cited in the previous point, 81% of youth between the ages of 15 and 20 sleep with their mobile phones turned on.
 4. The mobile phone is the only mass medium with a built-in payment mechanism.
4. The mobile phone is the only mass medium with a built-in payment mechanism.
Between the “app store” model for delivering applications and the fact that they’re tied to a networking provider that also acts as a billing agency, mobile phones are the first mass medium with a built-in toll booth. Even people too young to have credit cards can be billed; they can pay for purchases made via their phone through their phone bill with cash.
5. The mobile phone is the only mass medium available at the point of creative inspiration.
This is a direct by-product of mobile phones being always-on and always with us. Even those of us who carry our laptops everywhere have them tucked away in a carry case or bag, and I’m the rare person who always has a camera handy. While popular with the “lifehacker” crowd, not everyone carries a Moleskine notebook for jotting down ideas. But many people carry a mobile phone in an easy-to-reach place. It lets us create content in the form of writing, photos, and audio and video recordings in near real time. This is the basis of citizen journalism (whose effects were recently felt here in Toronto during the recent “cold war” between passengers of our rapid transit system and its employees).
6. The mobile phone is the only mass medium with accurate audience measurement.
“The internet gave us a false promise,” Ahonen writes, but audience measurement wasn’t what its creators had in mind. However, the mobile phone, it’s possible to know what every subscriber does since each is uniquely tied to a specific ID.
According to Ahonen:
- TV audience measurement can catch 1% of audience data
- Internet audience measurement can catch 10% of audience data
- Mobile phone audience measurement can catch 90% of audience data
7. The mobile phone is the only mass medium that captures the social context of media consumption.
By “social context of media consumption”, Ahonen means that with mobile phones, we can measure not just what people use, but with whom. It’s the next generation version of Amazon’s “recommendations” system and a direct result of mobile’s always-on, always-with-us, and audience measurement qualities.

, Edmonton (YEG), Calgary (YYC), Ottawa (YOW), Toronto (YYZ), Montreal (YUL)")




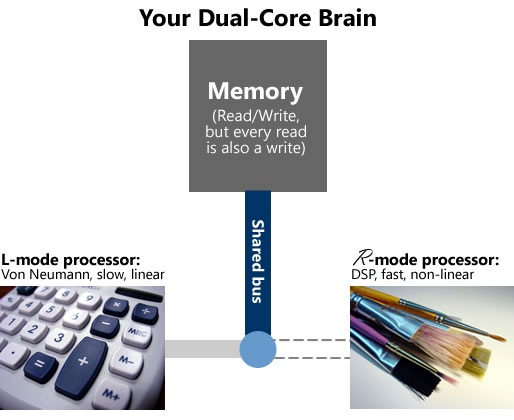
 Taking advantage of R-mode (often called the
Taking advantage of R-mode (often called the \"")

: A series about ideas for mobile apps")
 I think that the biggest challenge is going to be creating a new Windows Phone culture. I believe that one of the problems with the developer culture surrounding the old Windows Mobile was that they treated the mobile phone as simply a shrunken-down version of the desktop.
I think that the biggest challenge is going to be creating a new Windows Phone culture. I believe that one of the problems with the developer culture surrounding the old Windows Mobile was that they treated the mobile phone as simply a shrunken-down version of the desktop. 




