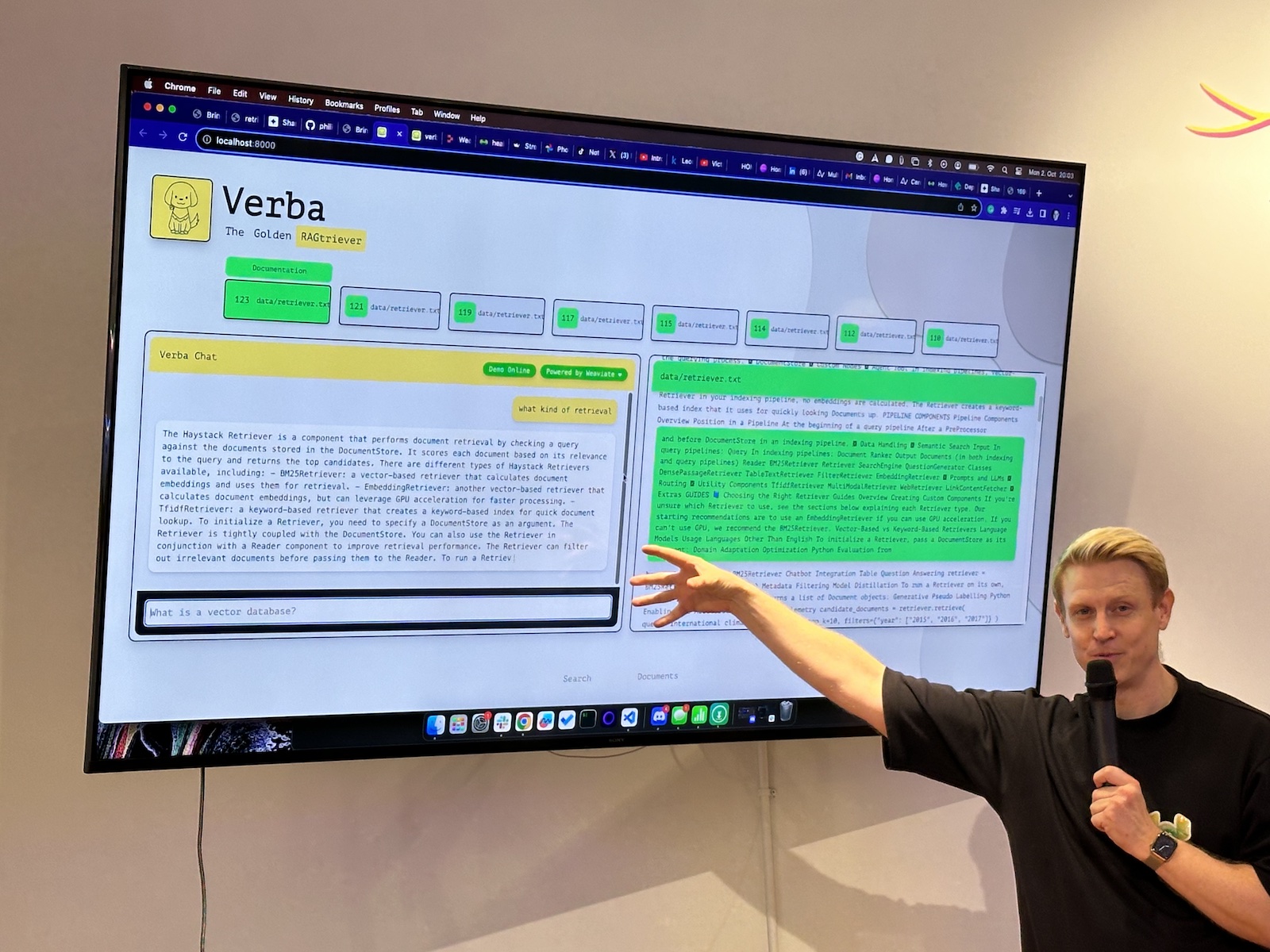
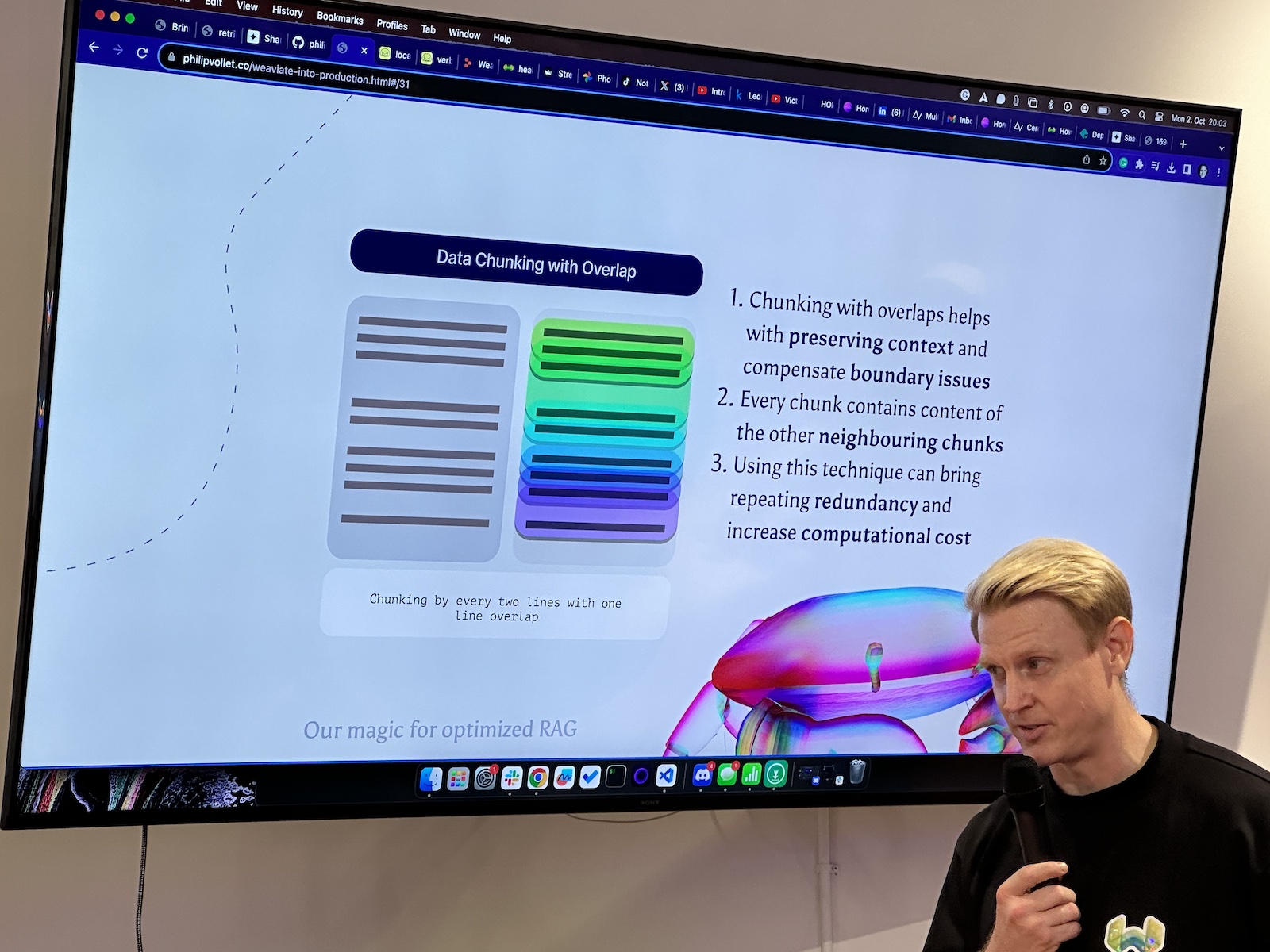
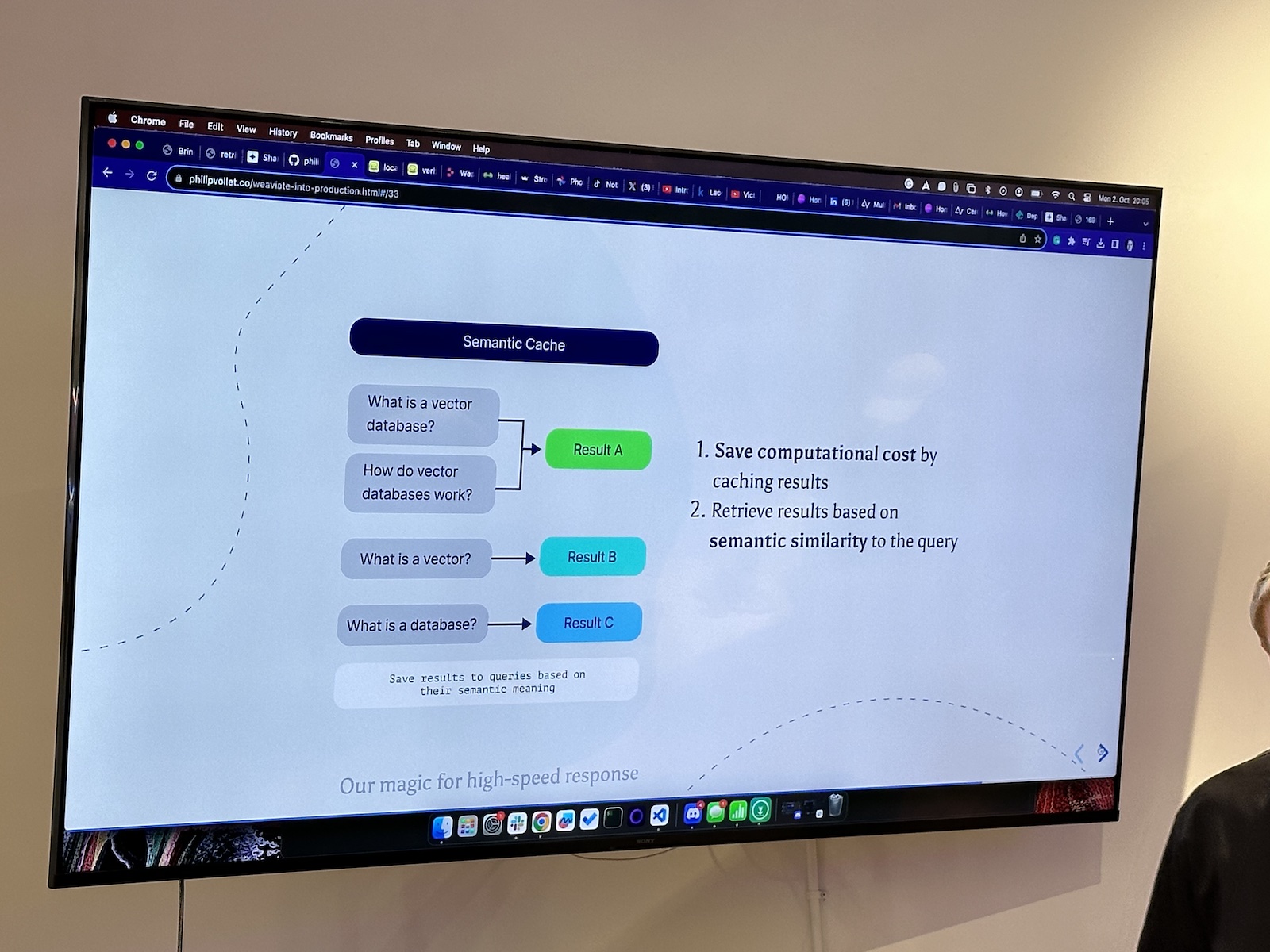
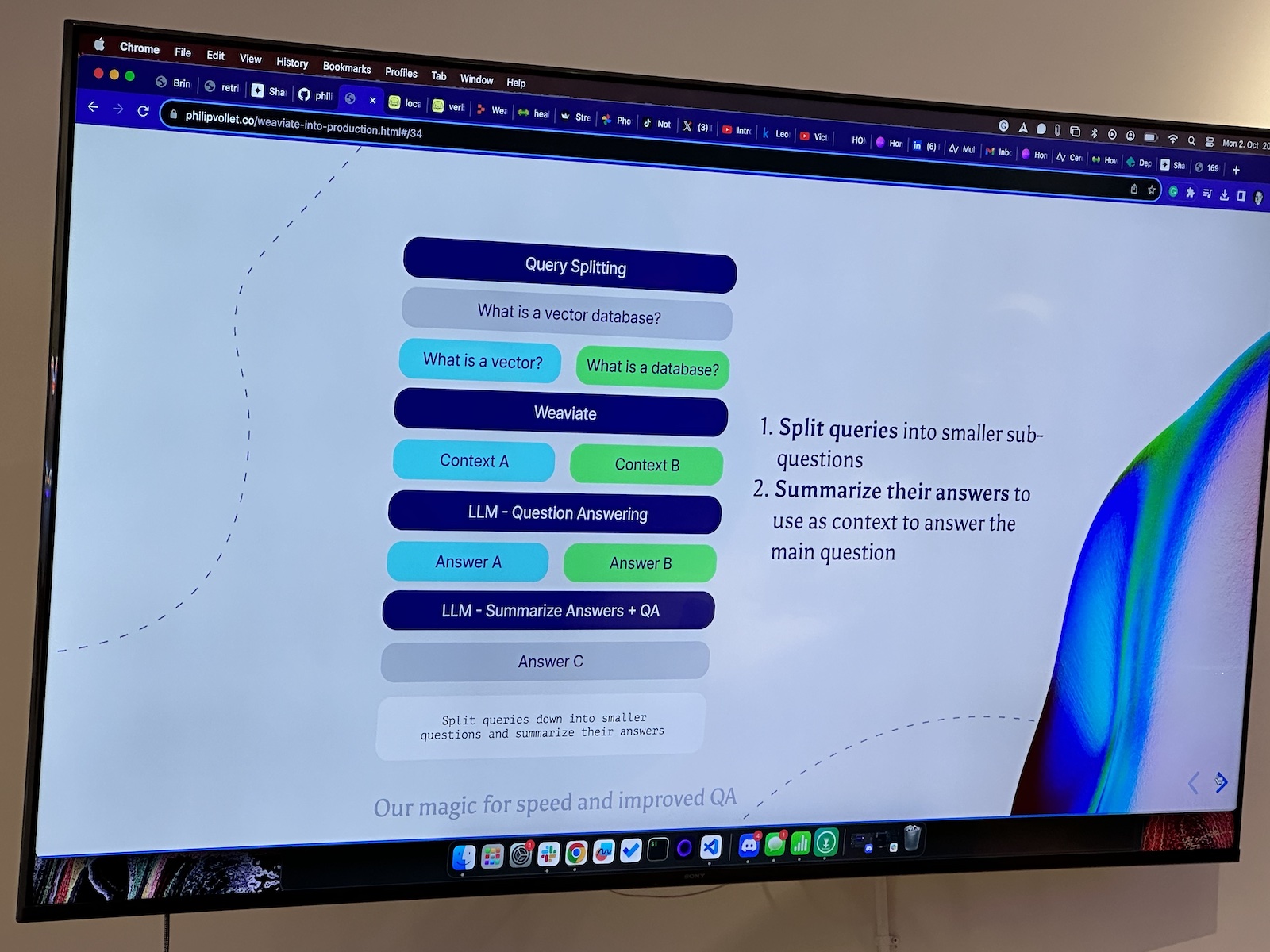
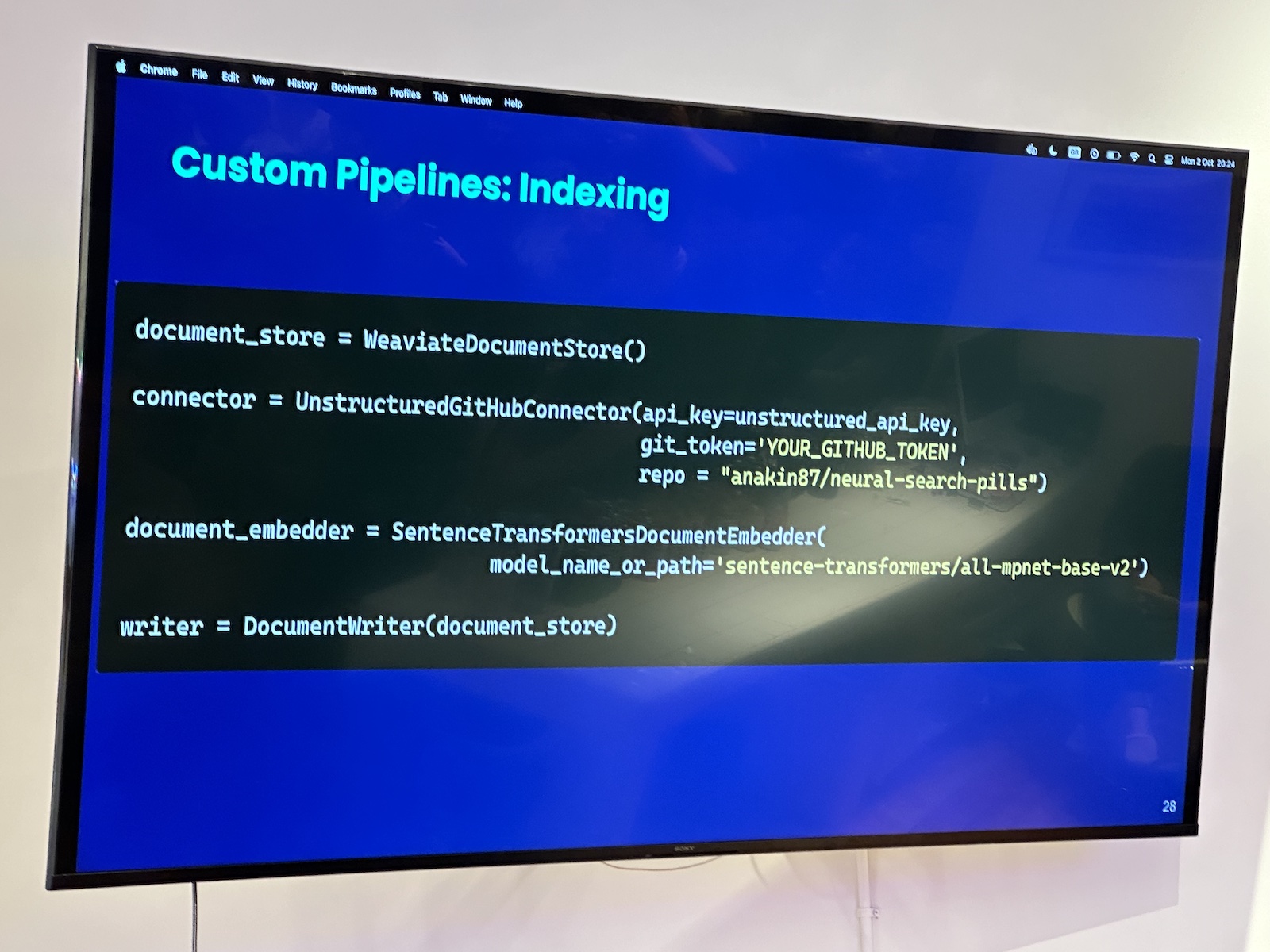
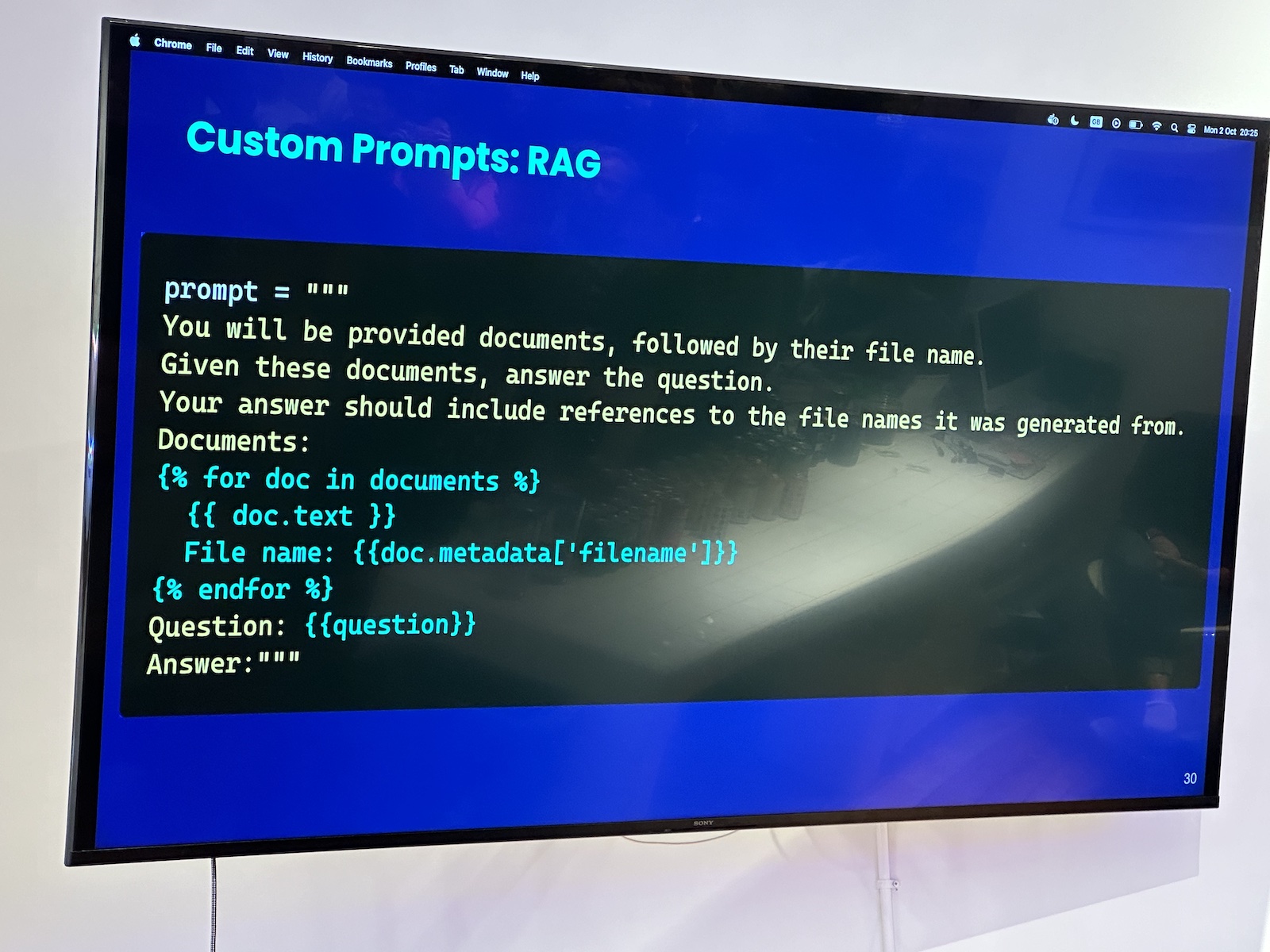
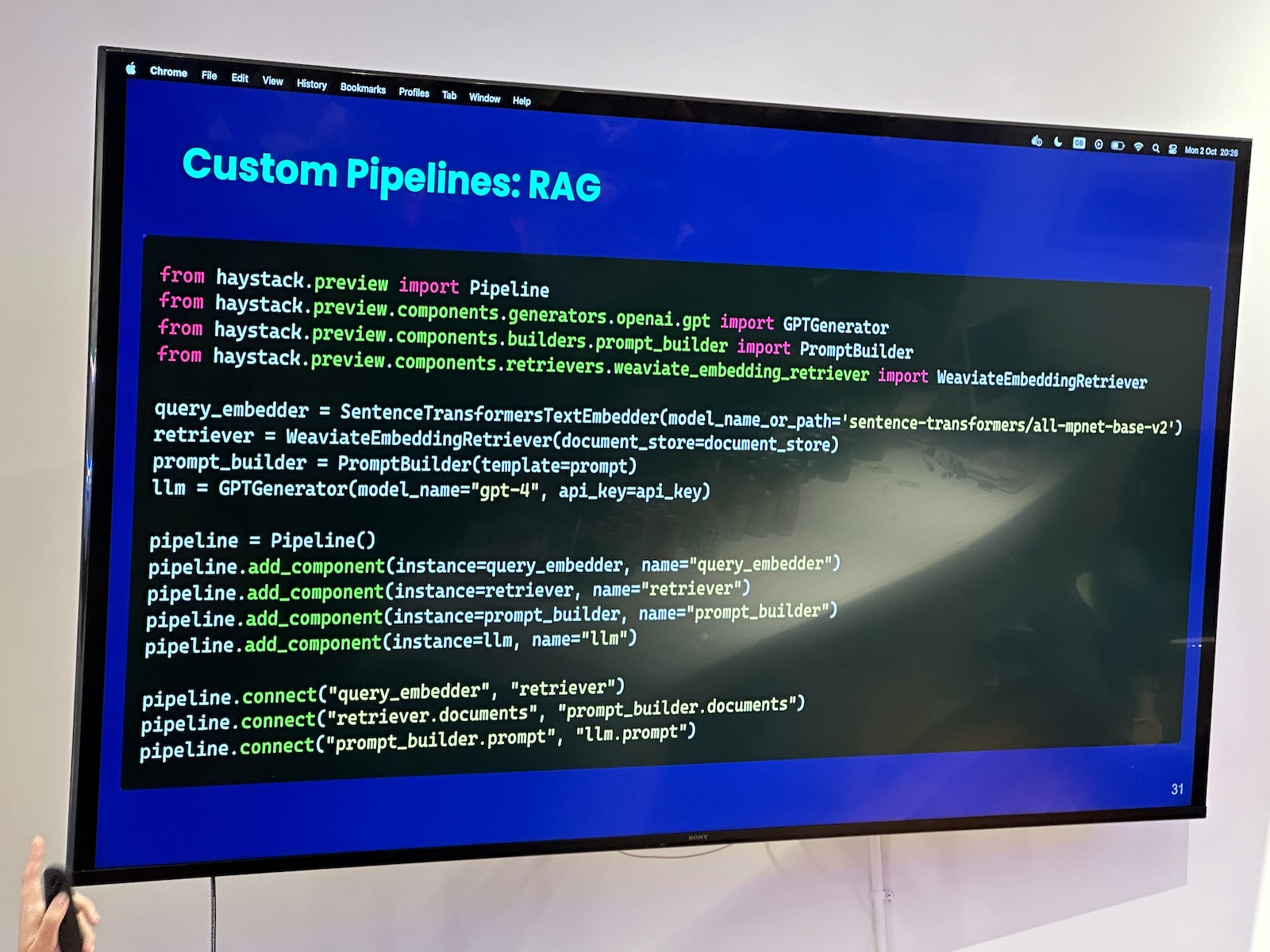
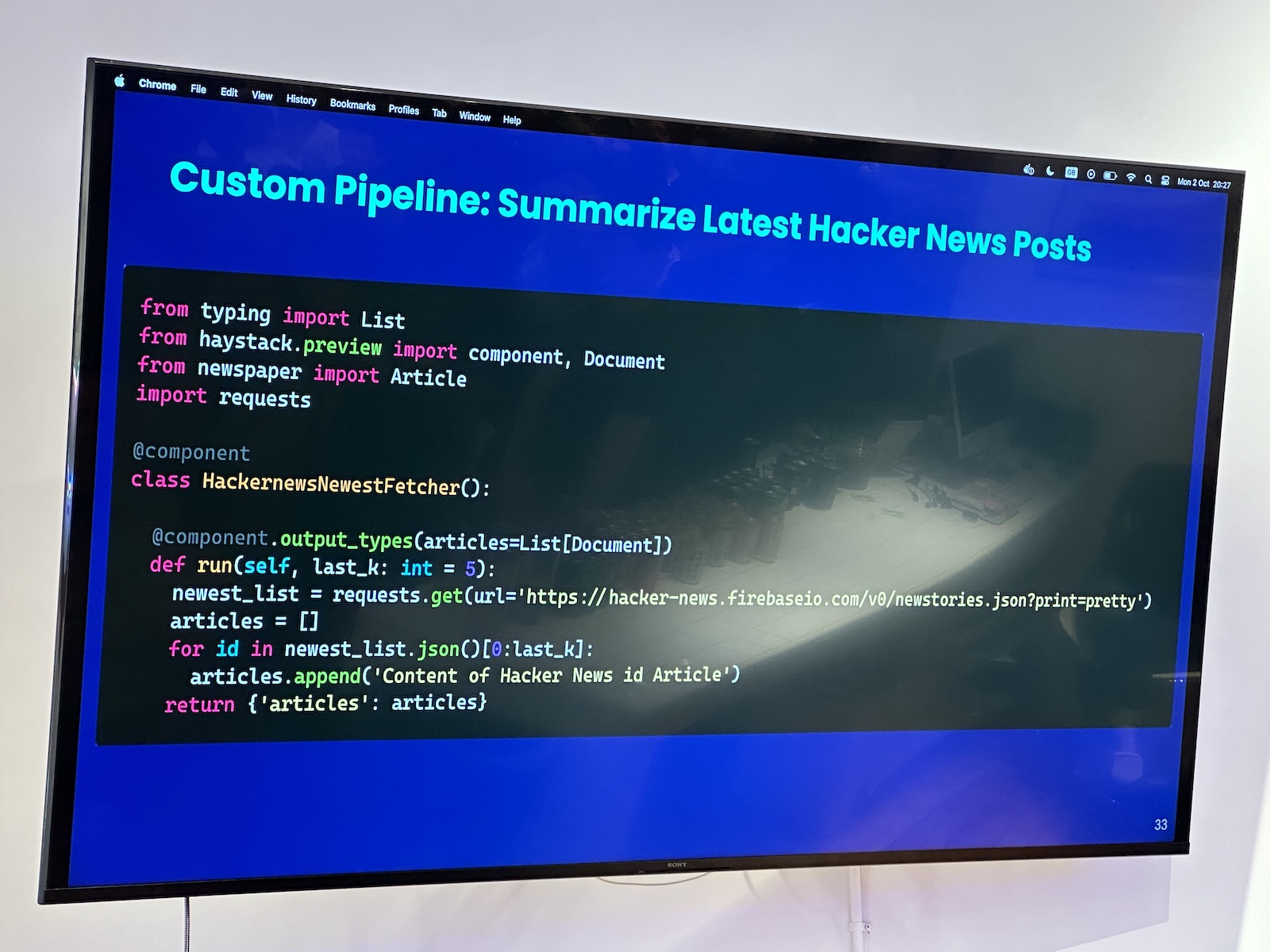
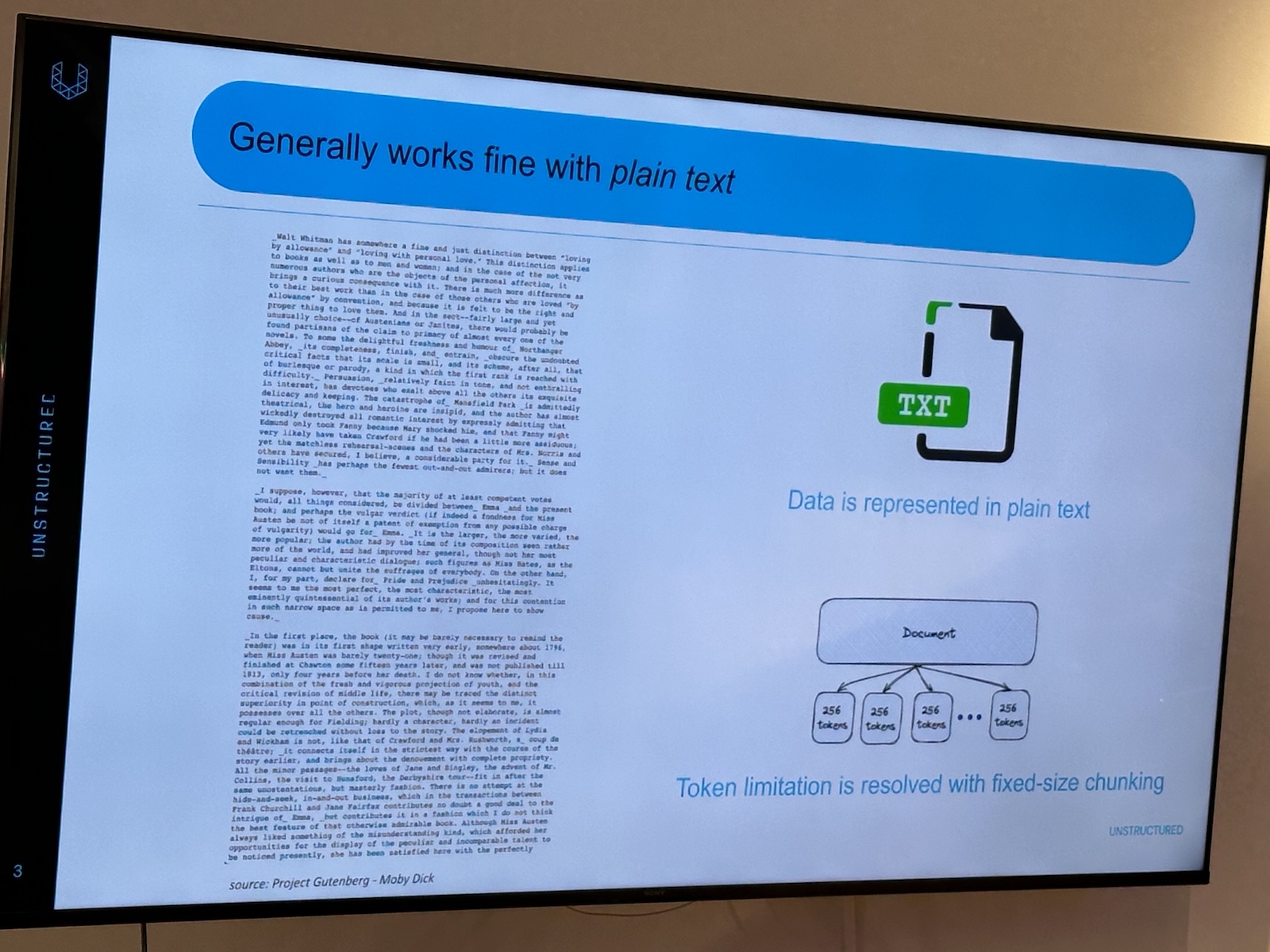
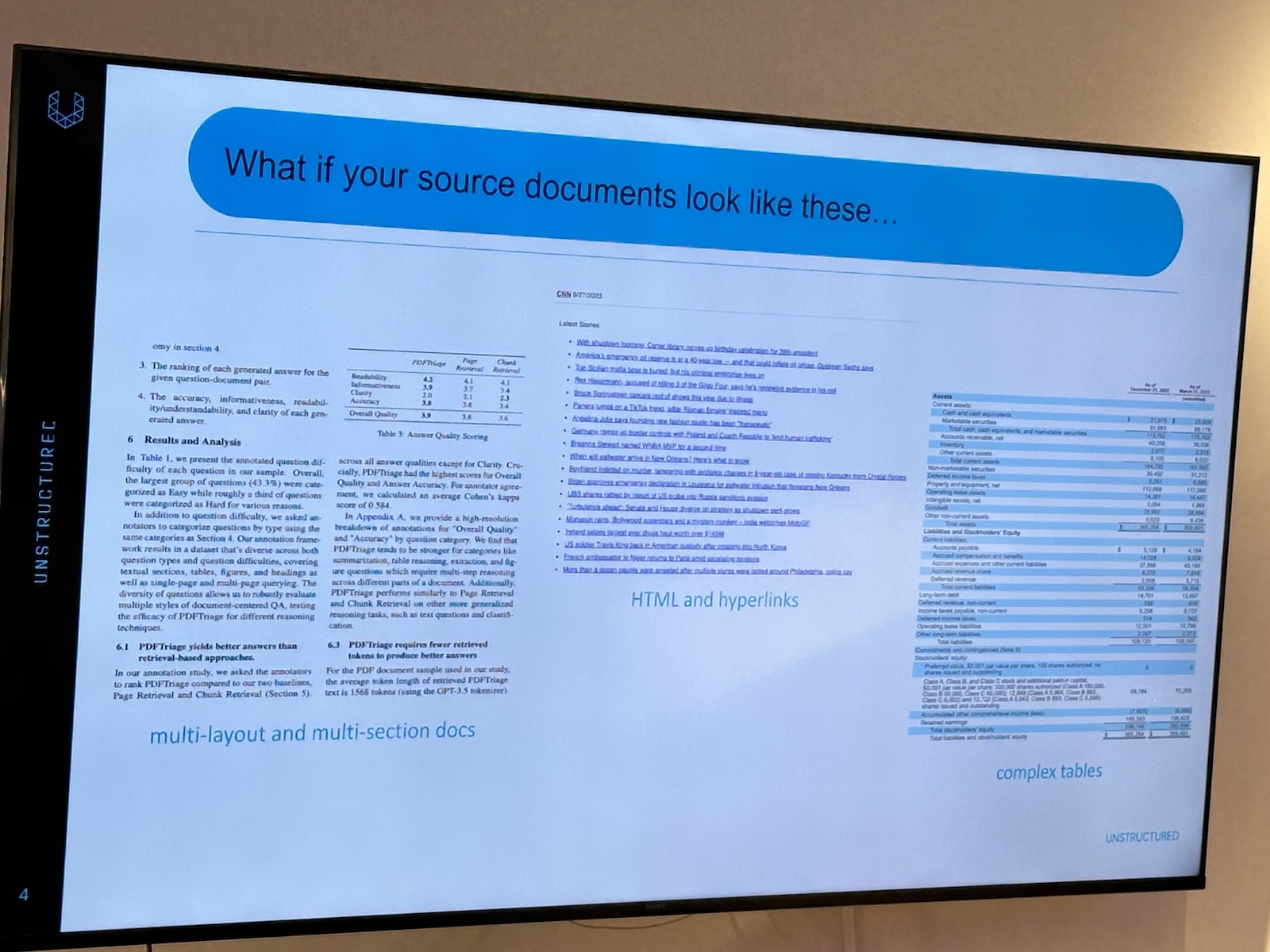
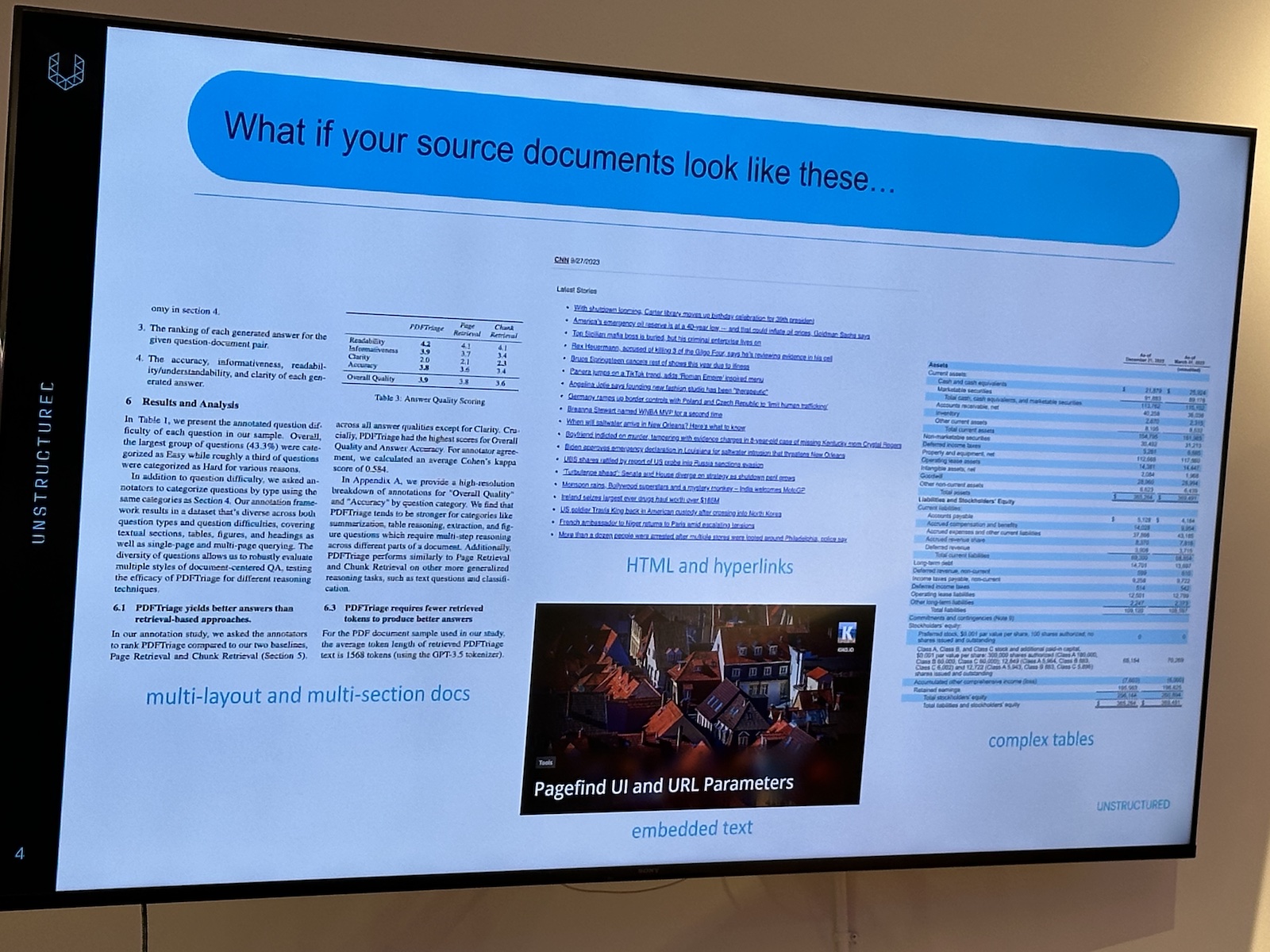
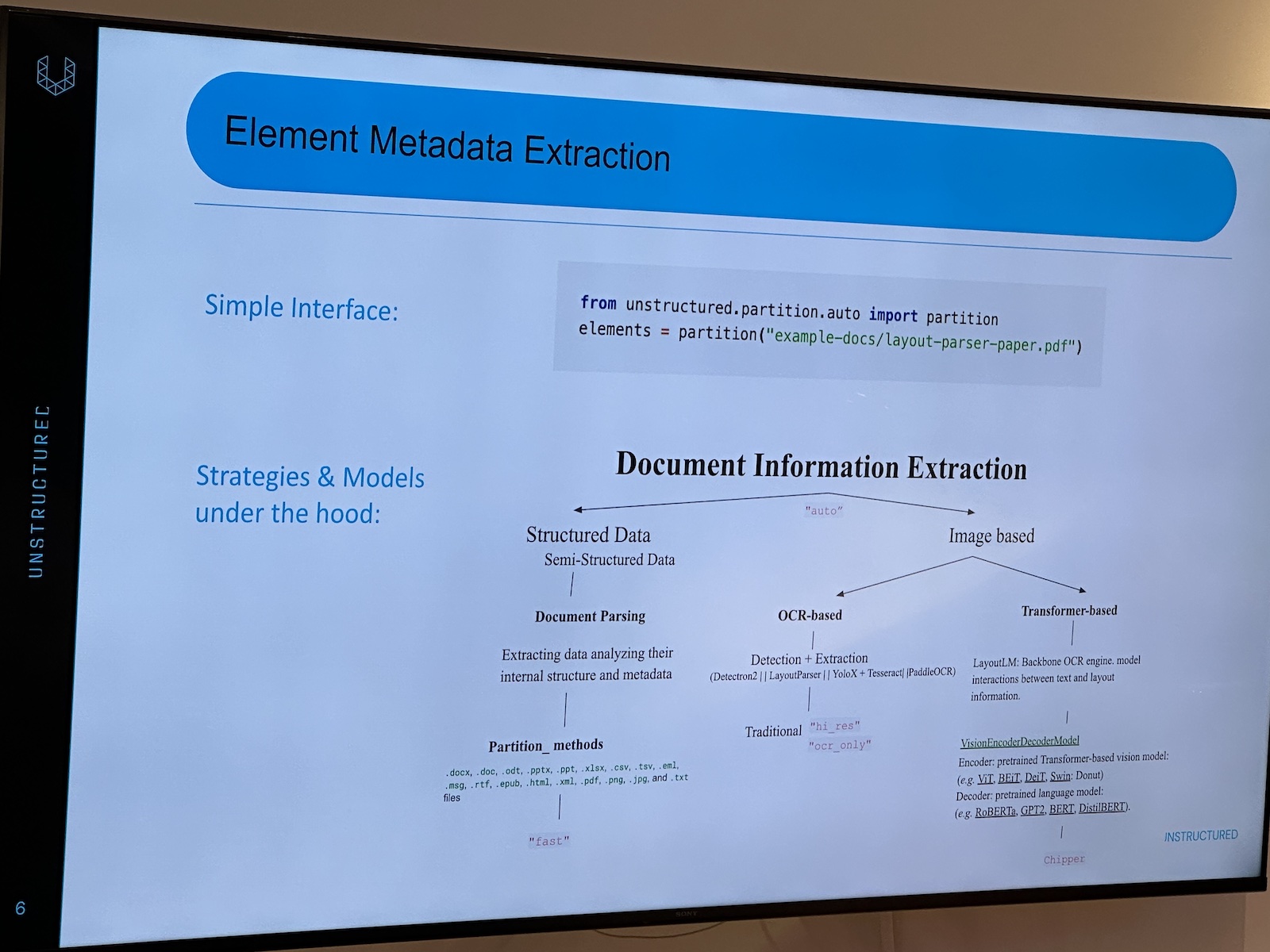
Here’s the “official unofficial” list of tech, entrepreneur, and nerd events for Tampa Bay and surrounding areas for Monday, January 29 through Sunday, February 4, 2024!

they’re also a great, developer-friendly cloud-native service provider!
Find out more.
Monday, January 29
| Event name and locale | Group | Time |
|---|---|---|
| Social Media Management Beginner Boot Camp Certification, Live Virtual Classroom | Tampa Social Media Enthusiasts | 10:00AM – Monday, Jan. 29 |
| In person at Fords Garage St Pete | Young Professionals Networking JOIN in and Connect! | 11:00AM – Monday, Jan. 29 |
| Networking at Ford’s Garage | Tampa Bay Networking and Events | 11:00AM – Monday, Jan. 29 |
| Downtown St Pete Business Professionals Lunch | Tampa / St Pete Business Connections | 11:00AM – Monday, Jan. 29 |
| Networking at Cafe’ Delanie | Tampa Bay Networking and Events | 11:30AM – Monday, Jan. 29 |
| Start the Week with more connections MONDAYS at Romi’s Tacos All Welcome! | Young Professionals Networking JOIN in and Connect! | 11:30AM – Monday, Jan. 29 |
| Business Networking Meeting | Christian Professionals Network Tampa Bay | 11:30AM – Monday, Jan. 29 |
| In PERSON Networking Lunch East Brandon Reserve your seat | Professional Business Networking with RGAnetwork.net | 11:30AM – Monday, Jan. 29 |
| Monday Business Introductions at Romi’s Taco’s | Tampa Bay Business Networking Meetings & Mixers | 11:30AM – Monday, Jan. 29 |
| Getting Started with Jira – Free Online Course | Tampa Cybersecurity Training | 6:00PM – Monday, Jan. 29 |
| Monday Feast & Game Night | Tampa Bay Tabletoppers | 6:00PM – Monday, Jan. 29 |
| Speakeasy Toastmasters #4698 | Toastmasters District 48 | 6:00PM – Monday, Jan. 29 |
| ROOKIES SPORTS BAR – SPRING HILL – LIVE TEAM TRIVIA !!! | America’s TriviAddiction | 6:00PM – Monday, Jan. 29 |
| Blood Rage w/Promo Monsters | Sarasota Strategy Board Game League | 6:00PM – Monday, Jan. 29 |
| MTG: Commander Night | Critical Hit Games | 6:00PM – Monday, Jan. 29 |
| Monday Weekly Board Game Night! (Lazy Moon Colonial Location) | Board Game Meetup: Board Game Boxcar | 6:00PM – Monday, Jan. 29 |
| January Viewing Party | Sarasota “Doctor Who” Fan Meetup | 6:00PM – Monday, Jan. 29 |
| North Port Toastmasters Meets Online!! | Toastmasters District 48 | 6:30PM – Monday, Jan. 29 |
| Monday Night One-Shot RPG: Tiny Living Dead | St Pete and Pinellas Tabletop RPG Group | 6:30PM – Monday, Jan. 29 |
| Three Bridges Brewing Trivia Night with the Smartphone Trivia Game Show | Game Night Meetup for Trivia in Tampa, Sarasota, Venice | 6:30PM – Monday, Jan. 29 |
| Board Game Night at Armada Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 7:00PM – Monday, Jan. 29 |
| Thomas Paine’s Annual Birthdate Celebration | Tampa Bay Coalition of Reason – dissolved | 7:00PM – Monday, Jan. 29 |
| Babylon Revisited | Comics, Animation and etc. | 7:00PM – Monday, Jan. 29 |
| Stirling Toastmasters Club #7461614 | Toastmasters District 48 | 7:00PM – Monday, Jan. 29 |
| Members as far back as 2008 can access their photos | School is closed- Light Study PRO – A Photography Workshop | 7:00PM – Monday, Jan. 29 |
| ONLINE: Stoic Poetry Slam | Orlando Stoics | 7:00PM – Monday, Jan. 29 |
| Online Event: Shut Up & Write!® Your Life Story (on Zoom) | Shut Up & Write!® St. Petersburg | 7:00PM – Monday, Jan. 29 |
| DigiMondays | Sunshine Games | 7:30PM – Monday, Jan. 29 |
| Weekly Meetup | Beginning Web Development | 8:00PM – Monday, Jan. 29 |
| Return to the top of the list | ||
Tuesday, January 30
| Event name and locale | Group | Time |
|---|---|---|
| Venice Area Toastmasters Club #5486 | Toastmasters District 48 | 7:30AM – Tuesday, Jan. 30 |
| v-Lean Coffee | Tampa Bay Agile | 7:30AM – Tuesday, Jan. 30 |
| NPI St. Pete Business Builders Chapter – Exchange Qualified Business Referrals | Network Professionals Inc. of South Pinellas (NPI) | 7:30AM – Tuesday, Jan. 30 |
| Becoming an Empowered AI Worker | Career Success Academy | 10:00AM – Tuesday, Jan. 30 |
| Becoming an Empowered AI Worker | Tech Success Network | 10:00AM – Tuesday, Jan. 30 |
| Becoming an Empowered AI Worker | Front End Creatives | 10:00AM – Tuesday, Jan. 30 |
| Becoming an Empowered AI Worker | Tampa Cybersecurity Training | 10:00AM – Tuesday, Jan. 30 |
| Brunch at The Wooden Rooster | St Petersburg Age 55 Plus Meet & Eat Women’s Group | 10:00AM – Tuesday, Jan. 30 |
| Westchase Business Networking Lunch ~ All Welcome JOIN us and connect! | Tampa / St Pete Business Connections | 11:00AM – Tuesday, Jan. 30 |
| Tuesday Westchase Business Networking Lunch at Sea Glass Tavern | Business Professionals of Pinellas, Pasco & Hillsborough | 11:00AM – Tuesday, Jan. 30 |
| Westchase Professional Business Networking Lunch ~ All Welcome | Young Professionals Networking JOIN in and Connect! | 11:00AM – Tuesday, Jan. 30 |
| Westchase Networking Lunch -Grand Hacienda~ Meet your next referral | Tampa Bay Business Networking Meetings & Mixers | 11:00AM – Tuesday, Jan. 30 |
| Networking at SeaGlass Tavern~ All Welcome, join us!!! | Tampa Bay Networking and Events | 11:00AM – Tuesday, Jan. 30 |
| Westchase Professionals Business Networking Lunch -Grand Hacienda 11955 Sheldon | Professional Business Networking with RGAnetwork.net | 11:30AM – Tuesday, Jan. 30 |
| Professional Business Networking Lunch Glory Day’s New Tampa | Pasco County Young Entrepreneurs/Business Owners All Welcome | 11:30AM – Tuesday, Jan. 30 |
| New Tampa Networking Lunch at Glory Day’s Grill New Tampa | Wesley Chapel, Trinity, New Tampa, Business Professionals | 11:30AM – Tuesday, Jan. 30 |
| Networking at Glory Days Grill | Tampa Bay Networking and Events | 11:30AM – Tuesday, Jan. 30 |
| New Tampa RGA Chapter ~ Glory Days Meet your next referral partner! | Professional Business Networking with RGAnetwork.net | 11:30AM – Tuesday, Jan. 30 |
| Networking at AppleBee’s St. Pete | Tampa Bay Networking and Events | 11:30AM – Tuesday, Jan. 30 |
| The Business Alliance Club | The Business Alliance | 11:45AM – Tuesday, Jan. 30 |
| Build Hyperledger Fabric Chaincode Better and Faster with the CC-Tools Lab | Hyperledger Tampa | 12:00PM – Tuesday, Jan. 30 |
| The Business Networking Midday Power Hour by Simply Referrals on Zoom!! | Simply Referrals Tampa Business Networking | 12:00PM – Tuesday, Jan. 30 |
| Six Figure Blueprint | Network After Work Tampa – Networking Events | 3:00PM – Tuesday, Jan. 30 |
| AI Walks into an XR Bar… | Tampa XR | 5:30PM – Tuesday, Jan. 30 |
| Dr. Tim Rayner Presents the Aviation Security Checkpoint | Science & Technology Society – Suncoast Region | 5:30PM – Tuesday, Jan. 30 |
| Startup Funding in Tampa, featuring Big Sky Capital VC & Seedfunders | Tampa Startup Founder 101 | 6:00PM – Tuesday, Jan. 30 |
| Getting Started with Jira – Free Online Course | Tech Success Network | 6:00PM – Tuesday, Jan. 30 |
| Weekly Open Make Night | Tampa Hackerspace | 6:00PM – Tuesday, Jan. 30 |
| Magic: The Gathering Night at Felicitous | Tampa Bay Gaming: RPG’s, Board Games & more! | 6:00PM – Tuesday, Jan. 30 |
| Getting Started with Jira – Free Online Course | Career Success Academy | 6:00PM – Tuesday, Jan. 30 |
| Getting Started with Jira – Free Online Course | Front End Creatives | 6:00PM – Tuesday, Jan. 30 |
| Tuesday Chess Meetup | Casselberry Kid-Friendly Chess Meetup | 6:00PM – Tuesday, Jan. 30 |
| Disney Lorcana: Rise of the Floodborn League Round 2 | Critical Hit Games | 6:00PM – Tuesday, Jan. 30 |
| Authors Anonymous – Writing Group | Authors Anonymous – Writing Group | 6:00PM – Tuesday, Jan. 30 |
| Loner Seekers Euchre – Tampa | Loner Seekers Euchre – Tampa | 6:30PM – Tuesday, Jan. 30 |
| Rug making class! | Makerspaces Pinellas Meetup Group | 6:30PM – Tuesday, Jan. 30 |
| Orlando ServiceNow Developer Meetup – Meet and Greet, 30th Jan, 06:30 – 8:30 PM | Orlando ServiceNow Developer Meetup | 6:30PM – Tuesday, Jan. 30 |
| Weekly Group Meetings – All Writers Welcome! | Pinellas Writers Group | 6:30PM – Tuesday, Jan. 30 |
| D&D Adventurers League at Armada Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 7:00PM – Tuesday, Jan. 30 |
| Yu-Gi-Oh Evening Tournament | Sunshine Games | 7:00PM – Tuesday, Jan. 30 |
| Music Bingo @ The Green Iguana Westshore | ► Tampa Bay Young Professionals Group | 7:00PM – Tuesday, Jan. 30 |
| Michael Fikaris | Comics, Animation and etc. | 7:00PM – Tuesday, Jan. 30 |
| Dunedin Toastmasters – Guests Welcome 👍🐛 | Dunedin Toastmasters 2166 | 7:00PM – Tuesday, Jan. 30 |
| Trivia Night – Moose Lodge 2117 Smartphone Trivia Game Show | Game Night Meetup for Trivia in Tampa, Sarasota, Venice | 7:00PM – Tuesday, Jan. 30 |
| Trivia Night with Trivia Nation | Trivia Night at Irish 31 Seminole | 7:00PM – Tuesday, Jan. 30 |
| St. Pete Beers ‘n Board Games Meetup for Young Adults | St. Pete Beers ‘n Board Games for Young Adults | 7:00PM – Tuesday, Jan. 30 |
| AMA – Ask Me Anything Related to Photography, Computers and Software | Florida Center for Creative Photography | 7:00PM – Tuesday, Jan. 30 |
| The Incal | Comics, Animation and etc. | 7:30PM – Tuesday, Jan. 30 |
| Let’s play chess at 54th Ave Kava House! | TB Chess – Tampa Bay – St. Petersburg Chess Meetup Group | 7:30PM – Tuesday, Jan. 30 |
| Online Event: Shut Up & Write on Zoom | Shut Up & Write!® Tampa | 7:45PM – Tuesday, Jan. 30 |
| Return to the top of the list | ||
Wednesday, January 31
| Event name and locale | Group | Time |
|---|---|---|
| 2024 Virtual Photo Challenge 1. In the year, 2023 | Florida Center for Creative Photography | 12:00AM – Wednesday, Jan. 31 |
| St Pete Networking Breakfast at the Hangar Meet St Pete’s Top Pro’s All Weclcome | Young Professionals Networking JOIN in and Connect! | 7:30AM – Wednesday, Jan. 31 |
| Networking at The Hanger Restaurant & Flight Lounge! | Tampa Bay Networking and Events | 7:30AM – Wednesday, Jan. 31 |
| NPI Profit Partners Chapter – Exchange Qualified Business Referrals | Network Professionals Inc. of South Pinellas (NPI) | 7:30AM – Wednesday, Jan. 31 |
| Downtown St Pete Professionals Networking Breakfast | Professional Business Networking with RGAnetwork.net | 7:30AM – Wednesday, Jan. 31 |
| Tampa Highrisers Toastmasters | Toastmasters District 48 | 7:45AM – Wednesday, Jan. 31 |
| Quantum Series Part 1: Introduction to Quantum Computing | Data, Cloud and AI in Tampa | 8:00AM – Wednesday, Jan. 31 |
| 1 Million Cups – Orlando Weekly Meetup | 1 Million Cups – Orlando | 8:30AM – Wednesday, Jan. 31 |
| Midjourney Prompt Help & Advanced FAQ with A.I. Creative Compass! | Midjourney A.I. Art Meetup Group | 11:00AM – Wednesday, Jan. 31 |
| Cyber threats to watch out for in 2024 | ManageEngine’s Cybersecurity Meetups | 11:00AM – Wednesday, Jan. 31 |
| In Person Networking BRANDON! Just Love Coffee Cafe – Brandon FL | Professional Business Networking with RGAnetwork.net | 11:15AM – Wednesday, Jan. 31 |
| Carrollwood Networking Lunch! Join us and win! | Tampa Bay Networking Meetings and Mixers | 11:30AM – Wednesday, Jan. 31 |
| Networking at Glory Days Grill! | Tampa Bay Networking and Events | 11:30AM – Wednesday, Jan. 31 |
| Brandon Networking Professionals Networking Lunch | Tampa Bay Business Networking Meetings & Mixers | 11:30AM – Wednesday, Jan. 31 |
| Carrollwood Professional Networking Lunch Wednesday All Welcome JOIN us | Professional Business Networking with RGAnetwork.net | 11:30AM – Wednesday, Jan. 31 |
| Networking at Just Love Coffee! | Tampa Bay Networking and Events | 11:30AM – Wednesday, Jan. 31 |
| Brandon Business Professionals Just Love Coffee | Young Professionals Networking JOIN in and Connect! | 11:30AM – Wednesday, Jan. 31 |
| Brandon Business Professionals IN Person!!!! | Tampa / St Pete Business Connections | 11:30AM – Wednesday, Jan. 31 |
| Business Networking Lunch | Bradenton/Sarasota Networking Meetings and Mixers | 11:30AM – Wednesday, Jan. 31 |
| Sarasota Business Networking Lunch All Welcome, Just purchase Lunch! | Network & Social – Orlando Networking Events | 11:30AM – Wednesday, Jan. 31 |
| National Association of Entrepreneurs Mastermind Group Meeting | National Association of Entrepreneurs Mastermind Group | 11:30AM – Wednesday, Jan. 31 |
| Lunch Hour Meetup | Sarasota Web Development Meetup Group | 12:00PM – Wednesday, Jan. 31 |
| Startup Ideation: Finding a Problem That Matters | Tampa Startup Founder 101 | 1:00PM – Wednesday, Jan. 31 |
| The Future of AI for Business Development, Sales & Marketing in 2024 | Network After Work Tampa – Networking Events | 1:00PM – Wednesday, Jan. 31 |
| Online Event: Shut Up & Write!® Your Life Story (on Zoom) | Shut Up & Write!® St. Petersburg | 1:00PM – Wednesday, Jan. 31 |
| Inspiring Authors & Book Immersion Meetup | Lady Lake Memoir Writing Meetup Group | 2:00PM – Wednesday, Jan. 31 |
| The Ultimate 2024 Client Acquisition Marketing Guide | Network After Work Tampa – Networking Events | 3:00PM – Wednesday, Jan. 31 |
| Image Comics | Comics, Animation and etc. | 4:00PM – Wednesday, Jan. 31 |
| Playing Games in the Alley | The Tampa Chapter of the Society for the Exploration of Play | 5:00PM – Wednesday, Jan. 31 |
| Wednesday Night Gaming | Brandon Boardgamers | 5:00PM – Wednesday, Jan. 31 |
| Bay pines toastmaster’s hybrid meeting | Bay Pines Toastmasters | 5:15PM – Wednesday, Jan. 31 |
| Felicitous Game Night w/Heritage Dim Sum | Tampa Game Nights | 5:30PM – Wednesday, Jan. 31 |
| Wednesday Board Game Night | Tampa Gaming Guild | 5:30PM – Wednesday, Jan. 31 |
| Felicitous Game Night w/Heritage Dim Sum | Tampa Bay Gaming: RPG’s, Board Games & more! | 5:30PM – Wednesday, Jan. 31 |
| Stringer | Comics, Animation and etc. | 5:30PM – Wednesday, Jan. 31 |
| Happy Hour – Luna Lounge at Bulla Gastrobar | South Asian Professional Women in Tampa Bay | 5:30PM – Wednesday, Jan. 31 |
| Casual Commander Wednesdays | Sunshine Games | 6:00PM – Wednesday, Jan. 31 |
| Hobby Night – Minis Painting Tips & Tricks at Armada Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 6:00PM – Wednesday, Jan. 31 |
| Board Game Night | Critical Hit Games | 6:00PM – Wednesday, Jan. 31 |
| Dungeons & Dragons One Shot Wednesdays | Clermont Nerd Games | 6:00PM – Wednesday, Jan. 31 |
| Waterdeep Dragonheist: Session Zero (Tier 1, APL 1) | Orlando Adventurer’s Guild | 6:00PM – Wednesday, Jan. 31 |
| Wine Down Wednesday – Ladies Night at Meeple Movers Board Game Cafe | Meeple Movers Gaming Group | 6:00PM – Wednesday, Jan. 31 |
| Board Game Night at Deadwords Brewing | Brews N Board Games | 6:00PM – Wednesday, Jan. 31 |
| Yoga in Midtown | ► Tampa Bay Young Professionals Group | 6:20PM – Wednesday, Jan. 31 |
| Learn how to solder by working on an electronics project | Makerspaces Pinellas Meetup Group | 6:30PM – Wednesday, Jan. 31 |
| Game Night! | Drunk’n Meeples the Social Tabletop (Board) Gamers | 6:30PM – Wednesday, Jan. 31 |
| Name of the Wind – Patrick Rothfuss final | The Weirder Things Book Club | 6:30PM – Wednesday, Jan. 31 |
| Castaways Euchre Club | Castaways Euchre Club | 6:50PM – Wednesday, Jan. 31 |
| Carrollwood Toastmasters Meetings meet In-Person and Online | Toastmasters District 48 | 7:00PM – Wednesday, Jan. 31 |
| MtG Modern Constructed at Armada Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 7:00PM – Wednesday, Jan. 31 |
| MakerFX Monthly Membership Meeting | MakerFX Makerspace | 7:00PM – Wednesday, Jan. 31 |
| Workshop Wednesdays. Come Craft with Us. | Unlucky Roll Cafe Board Game Meetup | 7:00PM – Wednesday, Jan. 31 |
| Nerd Night: Board Games and Beer at Deadwords Brewing | Adventures On Tap: TTRPGs and Board Games | 7:00PM – Wednesday, Jan. 31 |
| New Beginnings & Old Rivalries | Central Florida AD&D (1st ed.) Grognards Guild | 7:00PM – Wednesday, Jan. 31 |
| How to Express Yourself and Connect with People | Professionals Meetup For Networking And Social Skillsets | 7:00PM – Wednesday, Jan. 31 |
| Cardfight Vanguard!! OverDress Weekly | Sunshine Games | 7:30PM – Wednesday, Jan. 31 |
| Movie Night: The Mitchells vs. The Machines | Comics, Animation and etc. | 8:00PM – Wednesday, Jan. 31 |
| Return to the top of the list | ||
they’re also a great, developer-friendly cloud-native service provider!
Find out more.
Thursday, February 1
| Event name and locale | Group | Time |
|---|---|---|
| Business Over Breakfast ~ Happy Hangar IN PERSON JOIN US! | Wesley Chapel, Trinity, New Tampa, Business Professionals | 7:30AM – Thursday, Feb. 1 |
| Happy Hangar Early Bird Professionals Networking | Pasco County Young Entrepreneurs/Business Owners All Welcome | 7:30AM – Thursday, Feb. 1 |
| Wesley Chapel/Lutz networking breakfast | Professional Business Networking with RGAnetwork.net | 7:30AM – Thursday, Feb. 1 |
| LUTZ, FL – HAPPY HANGER CAFE THURSDAY NETWORKING | Tampa Bay Networking and Events | 8:00AM – Thursday, Feb. 1 |
| Clearwater Professional Networking Lunch | Business Professionals of Pinellas, Pasco & Hillsborough | 11:00AM – Thursday, Feb. 1 |
| The Founders Meeting where it all Began! JOIN us! Bring a guest and get a gift | Young Professionals Networking JOIN in and Connect! | 11:00AM – Thursday, Feb. 1 |
| Pinellas County’s Largest Networking Lunch and your invited! | Tampa Bay Networking and Events | 11:00AM – Thursday, Feb. 1 |
| Clearwater/Central Pinellas Networking Lunch JOIN us and connect your business | Tampa / St Pete Business Connections | 11:00AM – Thursday, Feb. 1 |
| Lutz / Wesley Chapel Professional Networking Lunch at Bahama Breeze! | Professional Business Networking with RGAnetwork.net | 11:30AM – Thursday, Feb. 1 |
| Wesley Chapel Professional Networking Lunch | Wesley Chapel, Trinity, New Tampa, Business Professionals | 11:30AM – Thursday, Feb. 1 |
| Leads Club Meeting | South Shore Leads Club | 11:30AM – Thursday, Feb. 1 |
| Lutz / Wesley Chapel Professional Networking Lunch at Bahama Breeze! | Pasco County Young Entrepreneurs/Business Owners All Welcome | 11:30AM – Thursday, Feb. 1 |
| Breakroom Bar & Grill 11:28 Doors open at 11:00am IN Person | Professional Business Networking with RGAnetwork.net | 11:30AM – Thursday, Feb. 1 |
| NPI Power Lunch – Exchange Qualified Business Referrals | Network Professionals Inc. of South Pinellas (NPI) | 11:30AM – Thursday, Feb. 1 |
| The Business Networking Midday Power Hour by Simply Referrals on Zoom!! | Simply Referrals Tampa Business Networking | 12:00PM – Thursday, Feb. 1 |
| Telecom Park Toastmasters #6745 | Toastmasters District 48 | 12:00PM – Thursday, Feb. 1 |
| Sarasota Speakers Exchange Toastmasters | Toastmasters District 48 | 12:00PM – Thursday, Feb. 1 |
| Commander Open Play Night at Armada Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 1:00PM – Thursday, Feb. 1 |
| RPG: Pathfinder Society at Meeple Movers Board Game Cafe | Meeple Movers Role-Playing Games (RPG) Group | 2:00PM – Thursday, Feb. 1 |
| Gulfport Scrabble and Social | Gulfport Scrabblers and Social | 5:00PM – Thursday, Feb. 1 |
| Thursday Night Gaming | Brandon Boardgamers | 5:00PM – Thursday, Feb. 1 |
| Tomb of Annihilation (T2-APL7) | Orlando Adventurer’s Guild | 5:30PM – Thursday, Feb. 1 |
| Pathfinder Society | Critical Hit Games | 6:00PM – Thursday, Feb. 1 |
| Central Florida Board Gaming at The Collective | Orlando Board Gaming Weekly Meetup | 6:00PM – Thursday, Feb. 1 |
| BABOK IIBA Tampa Bay Study Group | IIBA Tampa Bay | 7:00PM – Thursday, Feb. 1 |
| Operations Automation Office Hours | Tampa Robotic Process Automation Group | 7:00PM – Thursday, Feb. 1 |
| One Piece Thursdays | Sunshine Games | 7:00PM – Thursday, Feb. 1 |
| FABulous Thursdays | Sunshine Games | 7:00PM – Thursday, Feb. 1 |
| Fingerboard Meetup | Indica Cafe Events | 7:00PM – Thursday, Feb. 1 |
| Palm Harbor Toastmasters Club #8248 | Toastmasters District 48 | 7:00PM – Thursday, Feb. 1 |
| Thursday chess at 54th Ave Kava House! | TB Chess – Tampa Bay – St. Petersburg Chess Meetup Group | 7:00PM – Thursday, Feb. 1 |
| Yu-Gi-Oh Tournament | Balance Martial Arts and Gaming | 7:00PM – Thursday, Feb. 1 |
| Smartphone Trivia Game Show at Wilders Pizza | Game Night Meetup for Trivia in Tampa, Sarasota, Venice | 7:00PM – Thursday, Feb. 1 |
| Dungeons and Dragons with Donavan | Unlucky Roll Cafe Board Game Meetup | 7:00PM – Thursday, Feb. 1 |
| Live streaming production and talent | Live streaming production and talent | 7:00PM – Thursday, Feb. 1 |
| Tackle it in Ten – Entrepreneur Roundtables | Entrepreneur Round Table | 8:30AM – Thursday, Feb. 1 |
| 2024 Career Goal Setting Workshop Series: The Power & Benefits of Goals | Tech Success Network | 11:00AM – Thursday, Feb. 1 |
| 2024 Career Goal Setting Workshop Series: The Power & Benefits of Goals | Career Success Academy | 11:00AM – Thursday, Feb. 1 |
| 2024 Career Goal Setting Workshop Series: The Power & Benefits of Goals | Front End Creatives | 11:00AM – Thursday, Feb. 1 |
| 2024 Career Goal Setting Workshop Series: The Power & Benefits of Goals | Tampa Cybersecurity Training | 11:00AM – Thursday, Feb. 1 |
| Megacon Orlando 2024 | All For Nerds | 2:00PM – Thursday, Feb. 1 |
| Graphic Novel Discussion Group | Comics, Animation and etc. | 3:00PM – Thursday, Feb. 1 |
| Quantum Series Part 1: Introduction to Quantum Computing | Data, Cloud and AI in Tampa | 3:30PM – Thursday, Feb. 1 |
| The Gang goes to MEGACON! | Gaming.net | 4:00PM – Thursday, Feb. 1 |
| FREE Live Class- NPC Founder Nic Stover on PhotoMaster Live | Tampa Chapter of Nature Photography Classes | 5:00PM – Thursday, Feb. 1 |
| Java on ChatGPT: Building a Plugin From Scratch | Tampa Bay Generative AI Meetup | 5:30PM – Thursday, Feb. 1 |
| Java on ChatGPT: Building a Plugin From Scratch | Tampa Java User Group | 5:30PM – Thursday, Feb. 1 |
| TBDEG – Clean Code | Tampa Bay Data Engineering Group | 6:00PM – Thursday, Feb. 1 |
| 1st Thursday Networking Mixer, Romi’s Tacos & RGANetwork.net $10 cash at door | Tampa Bay Business Networking Meetings & Mixers | 6:00PM – Thursday, Feb. 1 |
| Business Happy Hour ~ Cafe Delanie 1st Thursday Every Month 6pm to 8pm | Young Professionals Networking JOIN in and Connect! | 6:00PM – Thursday, Feb. 1 |
| Practical use of ChatGPT | St Pete AI | 6:00PM – Thursday, Feb. 1 |
| After Hours Mixer Romi’s Tacos! All Welcome $10 cash | Tampa Bay Networking Meetings and Mixers | 6:00PM – Thursday, Feb. 1 |
| After Hours Networking Happy Hour! Romi’s Tacos New Location | Tampa Bay Business Networking Happy Hour/Meetings/Meet Up | 6:00PM – Thursday, Feb. 1 |
| BECMI Campaign | Brandon and Seffner area AD&D and OSR Group | 6:00PM – Thursday, Feb. 1 |
| BotC night at Hourglass Brewery at the Hourglass District | Sunshine Social Deduction Gaming | 6:00PM – Thursday, Feb. 1 |
| Learn to Play Maple Valley at Meeple Movers Board Game Cafe | Meeple Movers Gaming Group | 6:00PM – Thursday, Feb. 1 |
| Let’s Play Backgammon – Backgammon Casual Games | Sanford Backgammon Group | 6:00PM – Thursday, Feb. 1 |
| Writing Meetup | Tampa Free Writing Group | 6:30PM – Thursday, Feb. 1 |
| Tampa Bay Drupal & Web Technologies Q&A. Everyone welcome! | Tampa Bay Drupal User Group | 7:00PM – Thursday, Feb. 1 |
| Shopbot Safety and Usage (Members Only) | Tampa Hackerspace | 7:00PM – Thursday, Feb. 1 |
| Cowboy Bebop Live! | Gen Geek | 7:00PM – Thursday, Feb. 1 |
| New Year’s Book Club Meeting | Chan’s Book Club of Tampa Bay | 7:00PM – Thursday, Feb. 1 |
| How websites are made: an introduction to CSS for complete beginners | Florida Software School | 7:00PM – Thursday, Feb. 1 |
| St. Pete Arthouse Cinema Club – “2023 Sundance Film Festival Short Film Tour” | St. Pete Arthouse Cinema Club | 7:00PM – Thursday, Feb. 1 |
| February – The Crystal Cave | Books & Brews! | 7:00PM – Thursday, Feb. 1 |
| Last Call: A True Story of Love, Lust, and Murder in Queer New York – Elon Green | St. Pete Booze and Book Club | 7:30PM – Thursday, Feb. 1 |
| Return to the top of the list | ||
Friday, February 2
| Event name and locale | Group | Time |
|---|---|---|
| Improve your communication, listening, and leadership skills | Winter Park Toastmasters – Learn while having FUN! | 7:15AM – Friday, Feb. 2 |
| Caffeine & Connections: Friday Fuel for Black Professionals | Pinellas County Black Business Meetup Group | 8:00AM – Friday, Feb. 2 |
| A.C.T. Acquire Connections Today Morning Business Networking All Welcome! | Entrepreneurs & Business Owners of Sarasota & Bradenton | 8:45AM – Friday, Feb. 2 |
| Tampa Young Professionals Virtual Networking Friday Morning All WElCOME | Young Professionals Networking JOIN in and Connect! | 8:45AM – Friday, Feb. 2 |
| A.C.T. Acquire Connections Today Morning Virtual Business Networking | Network & Social – Orlando Networking Events | 8:45AM – Friday, Feb. 2 |
| Networking over breakfast | Tampa Bay Networking and Events | 9:00AM – Friday, Feb. 2 |
| Business over Breakfast Clearwater | Tampa Bay Networking Meetings and Mixers | 9:00AM – Friday, Feb. 2 |
| FBI ~ Friday Business Introductions at Largo Family Restaurant | Professional Business Networking with RGAnetwork.net | 9:00AM – Friday, Feb. 2 |
| Online Networking with Brandon Biz Pros | Brandon Biz Pros | 9:00AM – Friday, Feb. 2 |
| Toastmasters – Improve Speaking Skills & Build Confidence | Christian Professionals Network Tampa Bay | 9:30AM – Friday, Feb. 2 |
| Ms. Biz Connectz- business leaders brainstorm together | Ms. Biz Connectz- business leaders brainstorming together | 10:00AM – Friday, Feb. 2 |
| International Networking at McAlisters Deli every Friday | Tampa Bay Business Networking Meetings & Mixers | 11:30AM – Friday, Feb. 2 |
| Friday International Business Introductions at McAlisters Westshore | Professional Business Networking with RGAnetwork.net | 11:30AM – Friday, Feb. 2 |
| Westshore Business Networking Lunch at McAlisters Deli Every Friday All Welcome | Tampa Bay Networking and Events | 11:30AM – Friday, Feb. 2 |
| International Professionals Networking Meeting | Tampa / St Pete Business Connections | 11:30AM – Friday, Feb. 2 |
| Friday Business Introductions Tampa | Tampa Bay Networking Meetings and Mixers | 11:30AM – Friday, Feb. 2 |
| International Networking Westshore McAlisters Deli | Tampa Bay Business Networking Happy Hour/Meetings/Meet Up | 11:30AM – Friday, Feb. 2 |
| International Networking at McAlisters Deli every Friday | Business Professionals of Pinellas, Pasco & Hillsborough | 11:30AM – Friday, Feb. 2 |
| International Professionals Networking Meeting | Tampa / St Pete Business Connections | 11:30AM – Friday, Feb. 2 |
| Pokémon Tournament Battles for a Prize! | Orlando Pokemon Tournament Meet up | 2:00PM – Friday, Feb. 2 |
| WEEKLY FRIDAY NIGHT GAMING AT GAMER’S COMMAND | Brandon Boardgamers | 5:00PM – Friday, Feb. 2 |
| Board Game Night! | Clermont Nerd Games | 5:00PM – Friday, Feb. 2 |
| Lets Play Pokemon! | Lake Mary Pokemon Meetup Group Lets Play | 5:00PM – Friday, Feb. 2 |
| Friday Board Game Night | Tampa Gaming Guild | 5:30PM – Friday, Feb. 2 |
| Taps & Drafts | Casual EDH/MtG Social Night | Nerd Night Out | 6:00PM – Friday, Feb. 2 |
| GROWTH MINDSET | Self-Perfected Orlando | 6:00PM – Friday, Feb. 2 |
| Taps & Drafts | EDH/MtG Night | Centro Ybor | Nerdbrew Events | 7:00PM – Friday, Feb. 2 |
| Modern FNM | Sunshine Games | 7:00PM – Friday, Feb. 2 |
| PVP Boardgame Showdown | Unlucky Roll Cafe Board Game Meetup | 7:00PM – Friday, Feb. 2 |
| Friday Pokemon Tournament | Sunshine Games | 7:30PM – Friday, Feb. 2 |
| Friday night game night | Indica Cafe Events | 9:00PM – Friday, Feb. 2 |
| International Networking at McAlisters Deli every Friday | Tampa Bay Business Networking Meetings & Mixers | 11:30PM – Friday, Feb. 2 |
| First Friday WordPress Collaboration Meetup – February 2024 | West Orlando WordPress Meetup | 10:00AM – Friday, Feb. 2 |
| MEGACON Orlando 2024 | Asian Social Orlando | 10:00AM – Friday, Feb. 2 |
| Apex Systems – Overcoming Common Big Boulders Panel Discussion, Part 2 | IIBA Tampa Bay | 1:00PM – Friday, Feb. 2 |
| RPG: D&D Village of the Goblin Chief at Meeple Movers Board Game Cafe | Meeple Movers Role-Playing Games (RPG) Group | 4:30PM – Friday, Feb. 2 |
| Board Game Friday Night at Meeple Movers Board Game Cafe | Meeple Movers Gaming Group | 5:00PM – Friday, Feb. 2 |
| Kabuki: Dreams | Comics, Animation and etc. | 5:30PM – Friday, Feb. 2 |
| Murders At Karlov Manor | MtG Private Lounge Takeover! | Nerdbrew Events | 6:00PM – Friday, Feb. 2 |
| First Friday social meetup! | Defcon727 – Unleashing Cybersecurity | 6:30PM – Friday, Feb. 2 |
| IN-PERSON: “Stoicism and the Art of Happiness” (Chapter 1) | Tampa Stoics | 7:00PM – Friday, Feb. 2 |
| MakerFX Makerspace Soft Arts Guild | MakerFX Makerspace | 7:00PM – Friday, Feb. 2 |
| MTG: Murders at Karlov Manor Prerelease #1 | Critical Hit Games | 7:00PM – Friday, Feb. 2 |
| Tabletop: Friday Board Game Night | Oviedo Middle Aged Gamers (OMAG) | 7:00PM – Friday, Feb. 2 |
| Soul Circus Cowboys at The Salty Shamrock (Southern Rock) | Fun with Friends in Tampa Bay | 7:00PM – Friday, Feb. 2 |
| Mario Kart at Tampa Bay Grand Prix-Clearwater | Gen Geek | 8:00PM – Friday, Feb. 2 |
| James Joyce | Comics, Animation and etc. | 8:45PM – Friday, Feb. 2 |
| Return to the top of the list | ||
Saturday, February 3
| Event name and locale | Group | Time |
|---|---|---|
| Wake Up and Think Clearly Saturday morning share and discuss. | Central Florida Philosophy Meetup | 7:00AM – Saturday, Feb. 3 |
| Street Photography – N Ashley Drive – 9am – 2 Hours | Tampa Photography Group | 9:00AM – Saturday, Feb. 3 |
| Monthly In Person Group Meeting – All Writers Welcome! | Pinellas Writers Group | 9:00AM – Saturday, Feb. 3 |
| Saturday Chess at Wholefoods in Midtown, Tampa | Chess Republic | 9:30AM – Saturday, Feb. 3 |
| MEGACON Orlando 2024 | Gen Geek | 10:00AM – Saturday, Feb. 3 |
| I SEE THE LIGHT… Introduction to cinematic lighting. | Lights… Camera… TAMPA. Filmmaking Alliance | 10:15AM – Saturday, Feb. 3 |
| Coffee, Board Games, & Scrabble | Unlucky Roll Cafe Board Game Meetup | 10:00AM – Saturday, Jan. 27 |
| Navigating Success: Customer Journey tools & techniques Workshop | Entrepreneur’s Guild: Growing Your Business | 11:00AM – Saturday, Feb. 3 |
| Dungeon Crawl Classics RPG Campaign with Ray at Meeple Movers Board Game Cafe | Meeple Movers Role-Playing Games (RPG) Group | 12:00PM – Saturday, Feb. 3 |
| Winning The Week – 1st Meet | Winning The Week | 12:00PM – Saturday, Feb. 3 |
| FREE Fab Lab Orientation | Suncoast Makers | 1:30PM – Saturday, Feb. 3 |
| Y Read: Book Read Aloud | Library Book Clubs – OCLS | 1:30PM – Saturday, Feb. 3 |
| Pokémon Tournament Battles for a Prize! | Orlando Pokemon Tournament Meet up | 2:00PM – Saturday, Feb. 3 |
| Social climbing of Mount Chesseverest | Climbers of Mount Chesseverest | 2:30PM – Saturday, Jan. 27 |
| How To Get Paid To Review Amazon Products – Amazon Influencer Program | Tampa Amazon Seller Meetup Group | 1:00PM – Saturday, Feb. 3 |
| Laser Cutter Orientation (Members Only) | Tampa Hackerspace | 2:00PM – Saturday, Feb. 3 |
| In-Person Event: Free Robotics Workshop, Tampa, FL (7-12 Yrs) | In person Robotics Meetup Group For Kids | 2:00PM – Saturday, Feb. 3 |
| Cloud Cuckoo Land – Book Discussion | Tampa Bay Book Club | 2:00PM – Saturday, Feb. 3 |
| MTG: Murders at Karlov Manor Prerelease #2 | Critical Hit Games | 2:00PM – Saturday, Feb. 3 |
| Outside the Binary Boardgame Meetup at Critical Hit Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 3:00PM – Saturday, Feb. 3 |
| Marvel Champions Campaign at Meeple Movers Board Game Cafe | Meeple Movers Gaming Group | 5:00PM – Saturday, Feb. 3 |
| Golf Group – Star Wars: Force & Destiny & One-Shots | Oviedo Middle Aged Gamers (OMAG) | 5:00PM – Saturday, Feb. 3 |
| IN-PERSON: The Meditations by Marcus Aurelius (Book 8) | Orlando Stoics | 5:00PM – Saturday, Feb. 3 |
| Lets Play Pokemon! | Lake Mary Pokemon Meetup Group Lets Play | 5:00PM – Saturday, Feb. 3 |
| Lost Mines of Phandelver: Session 5 – DM Mike | Orlando Adventurer’s Guild | 5:30PM – Saturday, Feb. 3 |
| Sound Money Money Soirée | Tampa Bay Bitcoin | 6:00PM – Saturday, Feb. 3 |
| Community Hang-out Night | Nerdbrew Events | 6:00PM – Saturday, Feb. 3 |
| Yu-Gi-Oh Tournament | Balance Martial Arts and Gaming | 7:00PM – Saturday, Feb. 3 |
| TB CHIPS Poker Party | TB Chips – Poker | 7:00PM – Saturday, Feb. 3 |
| Yu-Gi-Oh Evening Tournament | Sunshine Games | 7:00PM – Saturday, Feb. 3 |
| Tampa Nerd Online Hang-out & Game Night! | Nerd Night Out | 7:00PM – Saturday, Feb. 3 |
| Movie Night: Akira | Comics, Animation and etc. | 8:00PM – Saturday, Feb. 3 |
| Speaker Series [UPDATE] | Tampa Bay Bitcoin | 10:00AM – Saturday, Feb. 3 |
| Return to the top of the list | ||
Sunday, February 4
| Event name and locale | Group | Time |
|---|---|---|
| IHOP Restaurant CRITICAL THINKERS SUNDAY BRUNCH | Suncoast Critical Thinking Discussion Group | 9:00AM – Sunday, Feb. 4 |
| Animation Nights New York presents Program 90 | Comics, Animation and etc. | 9:30AM – Sunday, Feb. 4 |
| Speaker Series [UPDATE] | Tampa Bay Bitcoin | 10:00AM – Sunday, Feb. 4 |
| Megacon Orlando 2024 | All For Nerds | 10:00AM – Sunday, Feb. 4 |
| Open Fly @ Purveyor | Tampa Bay Drone Club | 10:30AM – Sunday, Feb. 4 |
| Warhammer 40K | Clermont Nerd Games | 11:00AM – Sunday, Feb. 4 |
| Board Games at Big Storm in Odessa | Beyond Catan, A Group of Board Game Geeks | 12:00PM – Sunday, Feb. 4 |
| Venice Strategy Board Gamers | Board Games and Card Games in Sarasota & Bradenton | 12:00PM – Sunday, Feb. 4 |
| Sunday Chess at Grassroots Kava House in Ybor | Chess Republic | 2:00PM – Sunday, Feb. 4 |
| D&D Adventurers League at Critical Hit Games | Tampa Bay Gaming: RPG’s, Board Games & more! | 2:00PM – Sunday, Feb. 4 |
| Plotter CriCut vinyl cutting | Makerspaces Pinellas Meetup Group | 12:00PM – Sunday, Feb. 4 |
| Sunday Gaming | Tampa Gaming Guild | 1:00PM – Sunday, Feb. 4 |
| Introverts ‘Talk Slow’ | O-Town Introverts | 1:30PM – Sunday, Feb. 4 |
| In-Person Event: Free Robotics Workshop, Chapel, FL (7-12 Yrs) | In person Robotics Meetup Group For Kids | 2:00PM – Sunday, Feb. 4 |
| T-Shirts and Caps printing | Makerspaces Pinellas Meetup Group | 2:00PM – Sunday, Feb. 4 |
| MTG: Murders at Karlov Manor Prerelease #3 | Critical Hit Games | 2:00PM – Sunday, Feb. 4 |
| Winter Park Chess Meetup | Winter Park Social Chess Club | 2:00PM – Sunday, Feb. 4 |
| Pokémon Tournament Battles for a Prize! | Orlando Pokemon Tournament Meet up | 2:00PM – Sunday, Feb. 4 |
| St. Pete Arthouse Cinema Club – “Origin” – Feb 4, 2024, 03:00 PM | St. Pete Arthouse Cinema Club | 3:00PM – Sunday, Feb. 4 |
| Adult Game Night at Conworlds Emporium | Tarpon Springs Pop Culture & Gaming Meetup | 4:00PM – Sunday, Feb. 4 |
| Sunday Pokemon League | Sunshine Games | 4:00PM – Sunday, Feb. 4 |
| Sunday Game Day | Drunk’n Meeples West Pasco (Boardgames) | 4:30PM – Sunday, Feb. 4 |
| Lets Play Pokemon! | Lake Mary Pokemon Meetup Group Lets Play | 5:00PM – Sunday, Feb. 4 |
| Lankhmar: City of Adventure | Brandon and Seffner area AD&D and OSR Group | 5:00PM – Sunday, Feb. 4 |
| Continuing adventures in the setting of Symbaroum. | St Pete and Pinellas Tabletop RPG Group | 5:15PM – Sunday, Feb. 4 |
| IN-PERSON: A Walking Meditation – Causeway Trail | Tampa Stoics | 5:15PM – Sunday, Feb. 4 |
| Sew Awesome! (Textile Arts & Crafts) | Tampa Hackerspace | 5:30PM – Sunday, Feb. 4 |
| February West Volusia Networking Social | Volusia Young Professionals Group (covers East and West) | 6:00PM – Sunday, Feb. 4 |
| Open Game Night | Unlucky Roll Cafe Board Game Meetup | 6:00PM – Sunday, Feb. 4 |
| Dinner at Deccan Spice | Geekocracy! | 6:00PM – Sunday, Feb. 4 |
| A Duck Presents NB Movie Night | Nerd Night Out | 7:00PM – Sunday, Feb. 4 |
| Hidden Gems Night, Presented by A Duck! | Nerdbrew Events | 7:00PM – Sunday, Feb. 4 |
| NerdBrew Karaoke @ MacDinton’s! | Nerd Night Out | 9:30PM – Sunday, Feb. 4 |
| NerdBrew Karaoke @ MacDinton’s! | Nerdbrew Events | 9:30PM – Sunday, Feb. 4 |
| Return to the top of the list | ||
they’re also a great, developer-friendly cloud-native service provider!
Find out more.
About this list
How do I put this list together? It’s largely automated. I have a collection of Python scripts in a Jupyter Notebook that scrapes Meetup and Eventbrite for events in categories that I consider to be “tech,” “entrepreneur,” and “nerd.” The result is a checklist that I review. I make judgment calls and uncheck any items that I don’t think fit on this list.
In addition to events that my scripts find, I also manually add events when their organizers contact me with their details.
What goes into this list? I prefer to cast a wide net, so the list includes events that would be of interest to techies, nerds, and entrepreneurs. It includes (but isn’t limited to) events that fall under any of these categories:
- Programming, DevOps, systems administration, and testing
- Tech project management / agile processes
- Video, board, and role-playing games
- Book, philosophy, and discussion clubs
- Tech, business, and entrepreneur networking events
- Toastmasters and other events related to improving your presentation and public speaking skills, because nerds really need to up their presentation game
- Sci-fi, fantasy, and other genre fandoms
- Self-improvement, especially of the sort that appeals to techies
- Anything I deem geeky