
I caught the Fundamentals of Software Engineering in the Age of AI workshop yesterday at the Arc of AI conference’s workshop day, led by Nathaniel Schutta (cloud architect at Thoughtworks, University of Minnesota instructor) and Dan Vega (Spring Developer Advocate at Broadcom, Java Champion).
Nate and Dan are the co-authors a book on the subject, Fundamentals of Software Engineering, and they’re out here workshopping the ideas with developers who are living through the same AI-saturated moment we all are.
Fair warning: this post is long. The session was dense, the conversation was good, and I took a lot of notes.
Here’s part four of several notes from the all-day session; you might want to get a coffee for this one.
Here are links to my previous notes:
The afternoon session of this workshop shifted away from the technical and toward the personal: career management, professional skill-building, how to actually learn things in an industry that never stops changing, and how to stay sane while it’s all happening. Nathaniel Nate carried most of this section alongside Dan Dan, with some sharp contributions from the audience. It was a good room for this kind of conversation: people who’d been in the industry a while, who’d seen waves come and go, trying to figure out what the current wave means for them specifically.
You are your own career manager, and that’s non-negotiable
Dan opened by acknowledging what a lot of people in the room were probably thinking: the career path they imagined when they started — get good at coding, keep getting better at coding, code until retirement — is not the only path, and for a lot of people it turned out not to be the right one either.
His framework for figuring out what direction to go: pay attention to what actually energizes you when you’re working. What problems do you want to solve? Do you prefer building interfaces or working with data and algorithms? Does debugging a gnarly problem feel like a puzzle you want to crack, or a tax you want to stop paying? Do you like the creative side of software, or the precision and correctness side? Side projects, he argued, are one of the best ways to run these experiments without quitting your job to do it.
The paths he outlined go well beyond the traditional “developer or manager” binary: software architect, staff engineer, engineering manager, technical product manager, developer advocate (his own role), sales engineer, and the increasingly relevant entrepreneur. Each has a different center of gravity, and none of them requires you to stop being technical.
His advice for navigating toward one of these: walk backwards from where you want to be. If you want to be an architect in five years, figure out what that role actually requires, then map it back to what you should be doing in years three to five, and years one to two. You’re already doing the mental motion of decomposing complex problems. Apply it to your own career.
Nate added the practical mechanics: use your personal development budget. A lot of people don’t, often out of a quiet fear of standing out or seeming like they’re trying too hard. He was blunt about this: “If you’ve got it and you’re not using it, you’re leaving part of your comp on the table. Any good manager should be thrilled you want to get better at your job.”
The technology radar: a personal framework for staying current without losing your mind
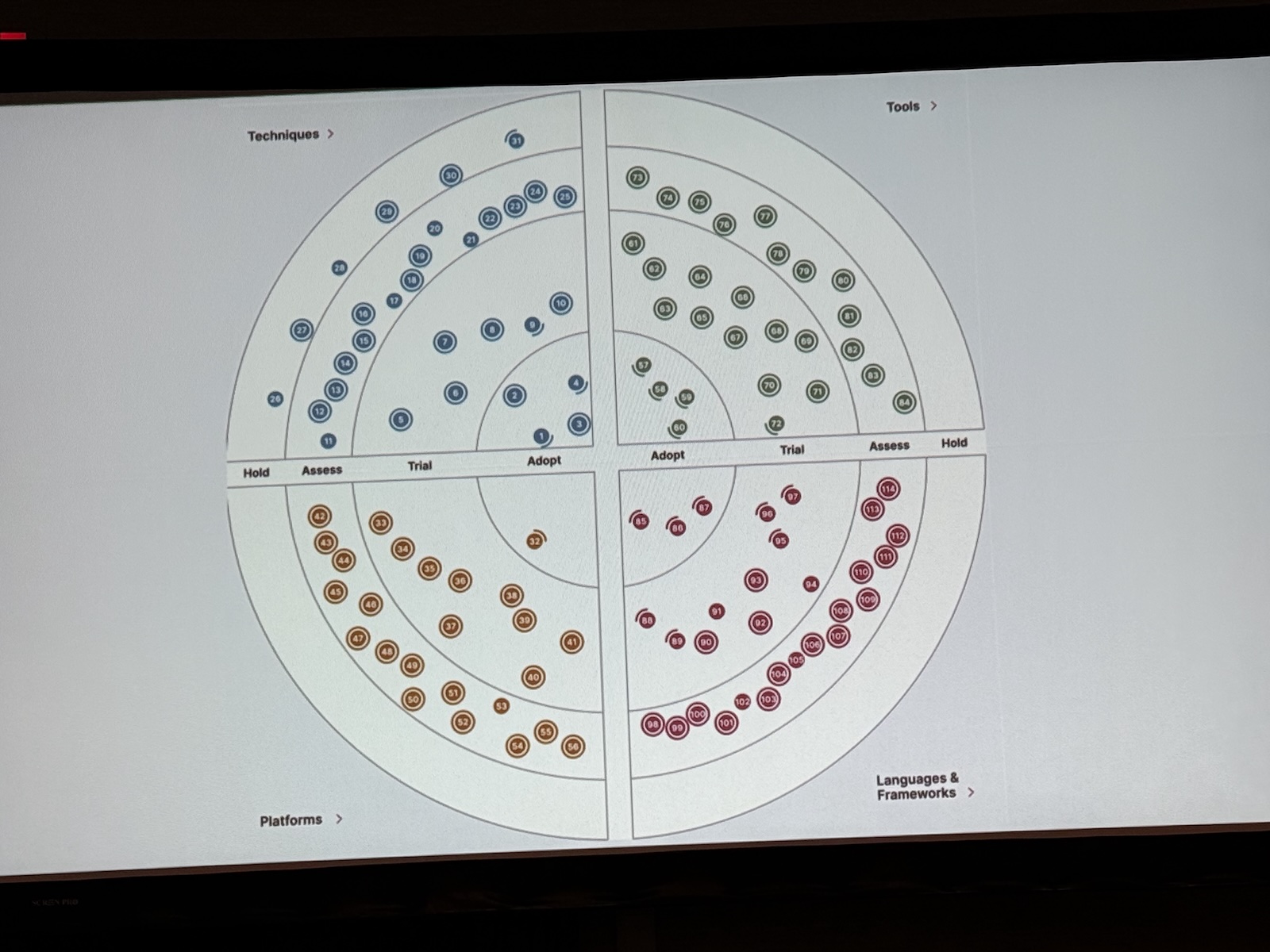
One of the more immediately actionable tools the workshop introduced was the Technology Radar concept. It’s familiar to a lot of people from Thoughtworks’s public-facing version, but here applied personally rather than organizationally.
The idea: organize technologies and techniques into four buckets. Adopt (things you’re currently using and mastering). Trial (things you’re actively experimenting with). Assess (things you’re watching but not diving into yet). Hold (things you’re deliberately not learning right now, even if people keep telling you to).
The audience exercise around this got interesting quickly. People shared their lists. “Rust on hold because Go is a higher priority at my company” was one contribution — and that’s exactly the right way to think about it. Your radar isn’t the same as someone else’s radar. Boris at Anthropic running five parallel Claude Code instances in his terminal doesn’t mean that’s the right workflow for you. Dan was emphatic: “Don’t see what someone else is doing and feel like you’re behind. You’re not.”
The schedule layer Nate added was useful: once you’ve identified something you want to learn, think through the cadence. Weekly, maybe a podcast or a short video. Monthly, maybe a meetup. Quarterly, maybe a deeper hands-on session. Annually, maybe a conference. Small, consistent investment over time beats cramming every time.
Record your wins, and be specific about the numbers
This was a section I wish someone had told me about fifteen years ago, and I suspect most people in the room felt similarly.
Dan’s recommendation: maintain a running wins document. Not elaborate. Not ceremonial. Just a note in Apple Notes or Google Docs where you record things you accomplished, feedback you received, skills you built, presentations you gave. The point is to have the material when you need it — annual reviews, promotion conversations, job searches, award nominations.
The key, and this is where most people go wrong: be specific, and attach numbers wherever possible.
“I improved performance in our flagship application” is forgettable. “I improved performance by 25% by implementing virtual threads” is a data point. “I reduced memory usage across a thousand instances over 300 apps” is a business case. The person making decisions about your raise or your promotion can’t make that case for you if you don’t give them the ammunition. Your manager is not necessarily keeping track of your contributions with the same level of care you are.
Nate extended this with a point about visibility: you want your manager to be able to walk into a room and tell a specific story about you. Not “Nate’s a solid engineer,” but “Nate’s Azure lunch and learn series pulled 200 people in the first session and our Chief Strategy Officer shared the metrics upward.” When your name comes up in rooms you’re not in, you want there to be a story attached to it — and that story needs to be true, specific, and ideally tied to a dollar amount or a measurable outcome.
His framing: “If your boss can say ‘Dan saved us 1.8 million dollars last year in Cloud costs,’ it’s a lot harder to put Dan on the non-regrettable attrition list.”
How we actually learn things (and why most approaches don’t work)

Nate took over for the learning science portion, and it was some of the best material of the day.
The core claim: in order to remember something, it needs to be elaborate, meaningful, and have context. Which is why story is so powerful — stories create context and meaning around facts that would otherwise evaporate. He mentioned that an AV technician once stopped him after a talk specifically to say she noticed he told stories, because most speakers just recite facts, and the stories were why she stayed engaged. He took that as confirmation of what he already believed: stories are the actual unit of memory, not information.
Spaced repetition matters. Brute-forcing your way through something until you think you’ve got it and then never returning to it is how you lose it. The Forgetting Curve is real. Little bits over time beats big chunks all at once. This is why blocking regular learning time on your calendar — Friday afternoons, Tuesday lunches, fifteen minutes of morning coffee before your day explodes — actually works where “I’ll get to it eventually” does not.
He was also honest about the limits of memory: forgetting is normal, not a personal failing. He now uses Gemini to re-explain things like OSI layers that he learned thirty years ago and hasn’t needed day-to-day. “I don’t freaking deal with it constantly. Getting a nice, concise refresher is fine, as long as I verify when it matters.”
The Dreyfus model of skill acquisition came up here, and it’s worth understanding. Five stages: novice (needs explicit recipes, follow the steps exactly), advanced beginner (can start combining recipes), competent (can troubleshoot, begins to self-correct), proficient (can self-correct in the moment), expert (operates on intuition, can’t always explain what they’re doing). The punchline: most developers don’t have ten years of experience; they have one year of experience ten times. And LLMs are permanently stuck somewhere around advanced beginner. They can combine recipes. They will never have intuition, the felt sense that something is wrong before you can articulate why.
Rules are essential for novices. Rules kill experts. A slightly different thing, checklists, are powerful across all levels, as the aviation and surgery examples illustrated. The distinction matters for how you think about AI-assisted development: AI needs guardrails because it can’t develop the intuition to know when to break the rules. You set the guardrails. That requires knowing the rules well enough to encode them.
You cannot read it all. Stop trying.
The death of a thousand subscriptions. Nate described the pile of unread magazines accumulating on his kitchen island and his wife’s gentle suggestion that most of it should go in the recycling as a near-perfect metaphor for the state of our industry’s information environment.
His rough estimate: the amount of content added to YouTube while the workshop was running would take more than a week to watch straight through, even without eating or sleeping. The amount of content added to the internet while they were in the room is unfathomable. Heat death of the universe is going to happen before you read it all.
His solution: cultivate a network of trusted people who read different things and share the signal. He and Glenn, he mentioned, exchange texts constantly, each person watching a different slice of the landscape, forwarding things worth attention. If something is genuinely important, it will hit you from multiple directions regardless. You don’t need to be first to every wave.
This connects back to the Technology Radar: FOMO is real, but you cannot surf every wave. Being a fast follower, letting other people take version 1.0 and joining at 1.1 once the shakeout has happened, is a completely legitimate strategy. The people who are struggling right now, Nate suggested, are the ones saying “nope, not my thing, not engaging,” and not the ones who are choosing deliberately where to focus.
On AI, anxiety, and not feeling like you’re behind
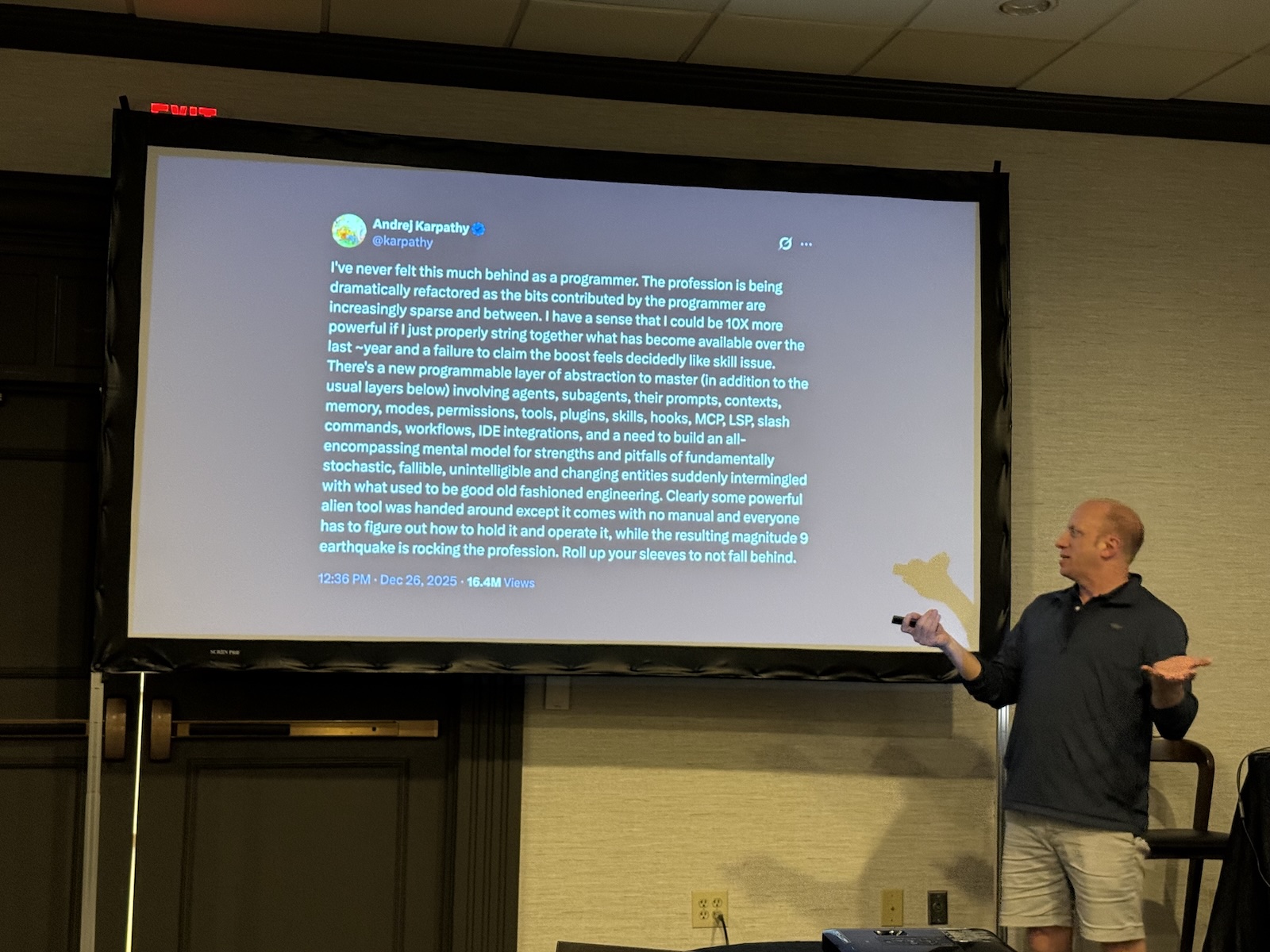
Dan closed with a section that felt necessary: acknowledgment that the current moment is genuinely overwhelming, and that AI fatigue is real even if nobody talks about it.
He referenced an Andrej Karpathy tweet about feeling like a powerful alien tool had been handed to everyone simultaneously without a manual, while a magnitude-9 earthquake is rocking the profession. Nobody knows how to hold it yet. The expectation that developers should now be 10x as productive is not a reality for most people. They’re still learning the tools, still figuring out what works, still dealing with the new cognitive load of evaluating AI output on top of doing the actual work.
His practical guidance on where to start, because the list of things you’re “supposed to know” (MCP, evals, prompt chaining, vibe coding, function calling, embeddings, constitutional AI, token sampling, and so on) is legitimately intimidating:
Start with playing with multiple models. Try the same prompt in Claude, Gemini, GPT. Notice the differences. That alone builds intuition. Then understand context and memory. What are the limitations of these systems, and how do you work within them? Then tools: the idea that you can give an LLM access to actions in the world. Then MCP servers as a way of packaging that capability. Then, eventually, agents and agentic workflows. But not before the foundational layers make sense.
And critically: don’t let someone else’s advanced workflow make you feel behind. The Boris-at-Anthropic-running-five-Claude-Code-instances workflow exists in a context you don’t share. Build your own relationship with these tools from wherever you actually are.
The closing argument

Nate closed the day, and I want to quote him here as directly as I can from my notes, because the framing was right:
“Fundamentals will always serve you well. I am adamantly of the opinion that they are even more important now than they were five years ago, and I thought they were pretty damn important five years ago when we started this book.”
Two mindsets available to you: define yourself by what you’ve done in the past, or define yourself by the problems you’re going to solve in the future. Reactive or proactive. Either way, change is coming. It always has been. He’s been doing this for almost thirty years and has not yet seen an instance where the industry just… stopped. The pendulum swings, the landscape shifts, and the people who navigate it best are the ones who maintain the fundamentals while staying curious enough to pick up the new tools.
He admitted he’s nervous about the cohort of people entering the industry right now: the steep drop in junior hiring, the Stanford placement numbers, the companies that have convinced themselves AI obsoletes entry-level work. But he thinks the snapback is coming. We need juniors to become seniors. Seniors don’t appear from nowhere. At some point, that math becomes undeniable.
His last line stuck with me: “I’d rather be the lead sled dog, because at least the view changes.”









 We’re All Using AI, But We’re Not Enjoying It takes an honest look at a growing gap in the workplace: AI adoption is skyrocketing, yet frustration, confusion, and uneven results are just as common. This talk explores why AI so often feels harder than it should—poorly integrated tools, unclear workflows, unrealistic expectations, cognitive overload, and the pressure to “keep up.” Looking at patterns seen across teams learning to use AI effectively, we’ll break down the practical barriers that make everyday AI work feel tedious instead of empowering. More importantly, we’ll outline a set of achievable shifts—better task design, lighter mental models, context-first prompting, workflow pairing, and small but meaningful guardrails—that can restore a sense of control and clarity.
We’re All Using AI, But We’re Not Enjoying It takes an honest look at a growing gap in the workplace: AI adoption is skyrocketing, yet frustration, confusion, and uneven results are just as common. This talk explores why AI so often feels harder than it should—poorly integrated tools, unclear workflows, unrealistic expectations, cognitive overload, and the pressure to “keep up.” Looking at patterns seen across teams learning to use AI effectively, we’ll break down the practical barriers that make everyday AI work feel tedious instead of empowering. More importantly, we’ll outline a set of achievable shifts—better task design, lighter mental models, context-first prompting, workflow pairing, and small but meaningful guardrails—that can restore a sense of control and clarity.





 Tampa Bay AI Meetup is a community partner of Arc of AI, and we can help you save $50 off the ticket price! Just use the discount code
Tampa Bay AI Meetup is a community partner of Arc of AI, and we can help you save $50 off the ticket price! Just use the discount code 