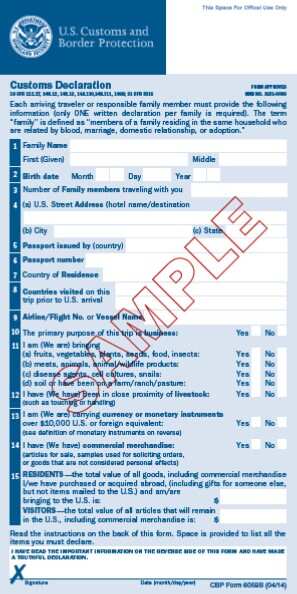
Welcome to another installment in my Advent of Code 2020 series, where I present my solutions to this year’s Advent of Code challenges!
In this installment, I share my Python solution to Day 4 of Advent of Code, a.k.a. “The Toboggan Puzzle”.
Spoiler alert!

Please be warned: If you want to try solving the challenge on your own and without any help, stop reading now! The remainder of this post will be all about my solution to both parts of the Day 4 challenge.
The Day 4 challenge, part one

The challenge
Here’s the text from part one of the challenge:
You arrive at the airport only to realize that you grabbed your North Pole Credentials instead of your passport. While these documents are extremely similar, North Pole Credentials aren’t issued by a country and therefore aren’t actually valid documentation for travel in most of the world.
It seems like you’re not the only one having problems, though; a very long line has formed for the automatic passport scanners, and the delay could upset your travel itinerary.
Due to some questionable network security, you realize you might be able to solve both of these problems at the same time.
The automatic passport scanners are slow because they’re having trouble detecting which passports have all required fields. The expected fields are as follows:
byr (Birth Year)iyr (Issue Year)eyr (Expiration Year)hgt (Height)hcl (Hair Color)ecl (Eye Color)pid (Passport ID)cid (Country ID)
Passport data is validated in batch files (your puzzle input). Each passport is represented as a sequence of key:value pairs separated by spaces or newlines. Passports are separated by blank lines.
Here is an example batch file containing four passports:
ecl:gry pid:860033327 eyr:2020 hcl:#fffffd
byr:1937 iyr:2017 cid:147 hgt:183cm
iyr:2013 ecl:amb cid:350 eyr:2023 pid:028048884
hcl:#cfa07d byr:1929
hcl:#ae17e1 iyr:2013
eyr:2024
ecl:brn pid:760753108 byr:1931
hgt:179cm
hcl:#cfa07d eyr:2025 pid:166559648
iyr:2011 ecl:brn hgt:59in
The first passport is valid – all eight fields are present. The second passport is invalid – it is missing hgt (the Height field).
The third passport is interesting; the only missing field is cid, so it looks like data from North Pole Credentials, not a passport at all! Surely, nobody would mind if you made the system temporarily ignore missing cid fields. Treat this “passport” as valid.
The fourth passport is missing two fields, cid and byr. Missing cid is fine, but missing any other field is not, so this passport is invalid.
According to the above rules, your improved system would report 2 valid passports.
Count the number of valid passports – those that have all required fields. Treat cid as optional. In your batch file, how many passports are valid?
Importing the data
Every Advent of Code participant gets their own set of data. I copied my data and went through my usual process of bringing it into Python. This involves pasting it into a triple-quoted string and assigning it to the variable raw_input.
raw_input = """pid:827837505 byr:1976
hgt:187cm
iyr:2016
hcl:#fffffd
eyr:2024
hgt:189cm byr:1987 pid:572028668 iyr:2014 hcl:#623a2f
eyr:2028 ecl:amb
pid:#e9bf38 hcl:z iyr:2029 byr:2028 ecl:#18f71a hgt:174in eyr:2036
hcl:#cfa07d byr:1982 pid:573165334 ecl:gry eyr:2022 iyr:2012 hgt:180cm
cid:151 hcl:#c0946f
ecl:brn hgt:66cm iyr:2013 pid:694421369
byr:1980 eyr:2029
ecl:brn
pid:9337568136 eyr:2026
hcl:#6b5442
hgt:69cm iyr:2019 byr:2025
cid:66 hcl:#efcc98 pid:791118269 iyr:2013
eyr:2020 ecl:grn hgt:183cm byr:1993
eyr:2022
hgt:160cm iyr:2016 byr:1969 pid:767606888 ecl:gry hcl:#6b5442
hgt:157cm eyr:2026 ecl:oth hcl:#efcc98 byr:1938 iyr:2014
byr:1931 iyr:2015
ecl:gry
hgt:76in
cid:227 hcl:#09592c eyr:2024 pid:276365391
ecl:gry hgt:170cm iyr:2014 cid:285 pid:870052514
hcl:#866857 byr:1925 eyr:2025
eyr:2021
byr:1960 pid:569950896
iyr:2010 hgt:179cm hcl:#888785 cid:167
hgt:154in cid:194
pid:8142023665 byr:2010 hcl:7d22ff ecl:utc iyr:2026 eyr:1976
ecl:blu eyr:2030 hgt:192cm
pid:363860866 iyr:2019 hcl:#ceb3a1 byr:1963
byr:1947 hgt:167cm hcl:#7d3b0c ecl:amb
cid:70 eyr:2022 iyr:2019 pid:756932371
hgt:185cm pid:871945454
iyr:2020
hcl:#866857 ecl:amb
byr:1989 cid:184 eyr:2030
byr:1935 pid:322117407
hgt:153cm iyr:2011
cid:244 eyr:2022 hcl:#efcc98 ecl:hzl
ecl:blu hcl:#5e6c12
eyr:2029 iyr:2011 hgt:191cm byr:1992
hcl:#7d3b0c eyr:2029
hgt:163cm
pid:625292172 byr:1932 ecl:brn
iyr:2020
hgt:158cm
eyr:2030 iyr:2016 byr:1969
cid:173 pid:092921211 hcl:#602927 ecl:grn
hcl:#733820
iyr:2016 eyr:2029
ecl:hzl hgt:180cm pid:292904469 byr:1984
ecl:amb pid:901224456 hgt:190cm
iyr:2013
hcl:#733820
byr:1922
pid:262285164 iyr:2010
byr:2018 eyr:2026 hcl:#602927 hgt:179cm ecl:gmt cid:349
byr:1956 eyr:2027 pid:351551997 hgt:71in cid:277 hcl:#cfa07d iyr:2010 ecl:grn
eyr:2027 hcl:#602927 hgt:157cm ecl:gry
cid:128 byr:1953
pid:231551549 iyr:2012
iyr:2011 pid:771266976
cid:264 byr:1955 hcl:#b6652a
hgt:189cm ecl:blu
eyr:2030
eyr:2026 pid:698455242
byr:1949 ecl:gry hgt:190cm
iyr:2013 hcl:#efcc98 cid:139
ecl:blu hgt:181cm byr:1977 iyr:2011 eyr:2022
pid:454163967 hcl:#b6652a
pid:534506872 hgt:155cm iyr:2012
byr:1968
cid:333 eyr:2024 hcl:#623a2f
ecl:amb
hgt:162cm
iyr:2020
hcl:#733820 eyr:2027 byr:1995 ecl:gry pid:084994685
iyr:2016 byr:1990
ecl:amb pid:185689022 eyr:2025
hgt:184cm hcl:#866857
byr:2016 hcl:z iyr:2022 hgt:166in
eyr:2040
byr:1943 hgt:152cm hcl:#cfa07d ecl:hzl iyr:2016 cid:300 pid:376088014
iyr:2020 eyr:2026 hcl:#602927 ecl:gry byr:1962 pid:453907789 hgt:172cm
eyr:2023 hgt:185cm
hcl:#623a2f pid:963767258 byr:1977
iyr:2019 ecl:oth
hgt:159cm byr:1965 cid:349 ecl:blu pid:962908167
iyr:2013 eyr:2024
hcl:#fffffd
eyr:2026
pid:912822238 hgt:66in byr:1985 iyr:2018 hcl:#c0946f ecl:hzl
hgt:167cm hcl:#ceb3a1
byr:1990 eyr:2027 ecl:grn
iyr:2011 pid:642877667
hcl:#7d3b0c byr:1921 pid:976412756 hgt:192cm
iyr:2013 ecl:gry
iyr:2030 pid:283599139
eyr:2039 cid:203
hcl:f943cb
hgt:111
hgt:190cm
iyr:2027 ecl:blu hcl:z
byr:2004 eyr:2039
pid:734570034
hcl:#6b5442 hgt:191cm
ecl:oth byr:1989 pid:669414669 cid:196 iyr:2016 eyr:2023
ecl:brn eyr:2028 byr:1965 pid:630674502 hcl:#602927 iyr:2020 hgt:61in
iyr:2016 eyr:2022 cid:225
hcl:#733820 ecl:hzl hgt:166cm
byr:1934
pid:232742206
ecl:amb hcl:#602927 eyr:2029
pid:897535300
hgt:189cm byr:1952
iyr:2017
pid:853604345
hgt:161cm cid:269
hcl:#fffffd eyr:2030 iyr:2011 ecl:grn byr:1966
hgt:151cm hcl:#18171d eyr:2026 ecl:grn iyr:2016 pid:176cm
byr:2000
hcl:#341e13
eyr:2022
pid:536989527 cid:73 byr:1971
ecl:hzl
pid:739005658 hcl:#b6652a
eyr:2026 hgt:154cm ecl:hzl
iyr:2019 byr:1935
pid:373465835 ecl:oth byr:1932 cid:333 hgt:165cm
hcl:#b6652a eyr:2021 iyr:2014
byr:1967 pid:486658617 hcl:#18171d hgt:174cm
eyr:2021 iyr:2015 ecl:gry cid:53
eyr:2024
cid:124 iyr:2017 hgt:152cm pid:095649305 hcl:#341e13
byr:1920 ecl:oth
hcl:#623a2f
byr:1951 pid:993284548
cid:106
hgt:186cm
ecl:amb iyr:2017 eyr:2029
cid:308 pid:080673934
hgt:193cm
byr:1967 hcl:#623a2f iyr:2016 ecl:hzl
eyr:2021
iyr:2010 eyr:2024 byr:1946 hgt:156cm
cid:199
ecl:blu hcl:#866857
ecl:blu byr:1955 eyr:2022 cid:95 pid:139391569
iyr:2019 hgt:180cm
hcl:#efcc98
ecl:brn pid:579889368
eyr:2023 hgt:158cm byr:1935
iyr:2018 hcl:#cfa07d
byr:1920 pid:90919899 hcl:#18171d
hgt:152cm
eyr:2029 ecl:oth iyr:2014
byr:1961 eyr:2024
ecl:#d401e3 iyr:2011 hgt:172cm pid:919145070
cid:100
hcl:#efcc98
ecl:gry
hgt:168cm
hcl:#888785 byr:1942 pid:731032830 iyr:2014
eyr:2028
hcl:#6b5442 pid:265747619 hgt:191cm
cid:217
eyr:2028
iyr:2019 ecl:amb
byr:1948
iyr:2011 ecl:brn
hgt:183cm hcl:#fffffd cid:258 byr:1983
pid:835909246
byr:2030
iyr:2024 ecl:#f66808
hcl:fd548d cid:183
pid:#fced33
hgt:160in
ecl:utc hgt:183in hcl:a92c31 pid:0394222041
iyr:2008
eyr:1976 byr:2020
pid:126195650 iyr:2019 hcl:#341e13
ecl:blu
hgt:150cm
eyr:2025
byr:1964
cid:71 iyr:2016 hgt:157 ecl:grt
hcl:#18171d pid:#1ab5ea eyr:2027
eyr:2026 hcl:#b5266f
byr:1971
cid:269 hgt:192cm iyr:2012
pid:736578840 ecl:amb
pid:152109472 hcl:#ceb3a1 ecl:grn hgt:188cm eyr:2027
byr:1923
hcl:#341e13 pid:535175953 hgt:63in eyr:2028 iyr:2015 byr:1999 ecl:gry
hgt:183cm pid:611738968 byr:2001
eyr:2020 hcl:#a97842 iyr:2014
ecl:gry
eyr:2038 ecl:gmt pid:113210210 iyr:2012 byr:2011
hcl:z
hgt:157cm
hgt:157cm
pid:699449127
iyr:2014 ecl:gry byr:1980 hcl:#fffffd eyr:2029
iyr:2028 hcl:z pid:152cm
eyr:2039
ecl:#4760fb hgt:177in
byr:2017
eyr:2026 hcl:#efcc98
iyr:2020 hgt:180cm ecl:hzl pid:747449965 byr:2016
byr:1974 iyr:2019
cid:89 eyr:2023 pid:421418405
hcl:#fffffd hgt:192cm
ecl:gry
hcl:26c2ef eyr:2029 cid:309 byr:1931 ecl:grn pid:#4eb099 iyr:2024
hgt:174cm
ecl:gry
hgt:183cm
cid:281
eyr:2022 pid:050492569
byr:1968 hcl:c88145
iyr:2015
eyr:2028
iyr:2014 pid:712984515 hgt:187cm cid:206 hcl:#866857 byr:1927
ecl:brn
byr:1936 hgt:61in ecl:oth iyr:2012 pid:447813841
hcl:#c0946f
cid:126 eyr:2021
ecl:gry pid:791970272
eyr:2020
byr:1932 hcl:#623a2f hgt:161cm
iyr:2015
hcl:#c0946f
byr:1935 pid:721144576 eyr:2025 hgt:162cm
iyr:2017 ecl:oth
byr:1959
pid:551109135
ecl:hzl hgt:68in
eyr:1977 hcl:#888785
iyr:1955 cid:100
hgt:190in eyr:1993 pid:8358180772 iyr:1975
ecl:oth
byr:2024
hcl:3de172
eyr:2030 hgt:190cm hcl:#a40ef3 byr:1935 pid:484932501
ecl:amb iyr:2016
iyr:2015
byr:1964
hgt:176cm
pid:819552732 hcl:#c0946f ecl:amb cid:263
eyr:2024
hgt:65cm cid:59 eyr:2027 pid:074880819 ecl:utc iyr:2023
byr:1954 hcl:#623a2f
byr:1954 hgt:167cm iyr:2020
eyr:2023 hcl:#602927
pid:280295309
ecl:hzl cid:168
hgt:168cm pid:311043701 iyr:2017 byr:1965
ecl:hzl
eyr:2026 hcl:#fffffd
hcl:#fffffd ecl:grn pid:672987232 iyr:2012 eyr:2022 hgt:66in
iyr:2012 ecl:#6f4f9f
hgt:133 byr:1937
eyr:1953 pid:7177768428 hcl:#602927
iyr:2010
byr:1922 hcl:#c0946f
eyr:2029 ecl:gry
hgt:165cm
pid:893045052
iyr:2013 eyr:2028 hcl:#866857 pid:137143403
ecl:brn hgt:170cm byr:1940 cid:194
hgt:161cm
eyr:2027 pid:3966920279 ecl:gry iyr:2015 byr:1997 hcl:#cfa07d
ecl:amb
hgt:157cm byr:1971
pid:562746894 cid:305 hcl:#0b0e1a eyr:2021 iyr:2016
hcl:8b821d hgt:157cm pid:187cm cid:298 eyr:1926 iyr:2019
ecl:amb
byr:2030
hgt:155cm hcl:#341e13 byr:1924 pid:779847670
ecl:hzl iyr:2015
eyr:2024
pid:768590475 hcl:#a97842 iyr:2014 cid:128 eyr:2029
ecl:oth hgt:164cm byr:1990
iyr:2019 hgt:181cm cid:342
eyr:2020 ecl:gry byr:2001
hcl:#623a2f
pid:473165431
byr:1928 eyr:2026 hcl:#42a9cb iyr:2010
ecl:grn hgt:157cm pid:638074984
eyr:2028
byr:1951
pid:239781647 iyr:2020 hgt:156cm
ecl:hzl cid:215 hcl:#efcc98
pid:636605355 ecl:hzl
iyr:2017 cid:323 eyr:2025
byr:1995
hcl:#18171d hgt:187cm
byr:1933 hcl:#866857 hgt:152cm ecl:oth iyr:2014 pid:900790914 eyr:2030 cid:267
ecl:brn byr:1999 eyr:2027 hcl:#623a2f iyr:2017
pid:853165955
hgt:152cm
eyr:2030 pid:316704688 hcl:#c0946f ecl:brn iyr:2014 hgt:193cm
iyr:2012 byr:1928
hgt:154cm pid:570535769 hcl:#623a2f eyr:2026 ecl:hzl
iyr:2016 cid:252 eyr:2030 hcl:#888785
hgt:177cm ecl:grn byr:2002 pid:568715162
pid:570999226 iyr:2012 hgt:150cm
byr:2024
ecl:brn hcl:z eyr:2029
pid:174002299 iyr:2019 hcl:#cfa07d ecl:brn byr:1927
cid:77 hgt:159cm eyr:2027
ecl:#d16191 eyr:2022 pid:166cm hgt:165cm hcl:#18171d iyr:2015
pid:112585759
hcl:#341e13 eyr:2025 byr:1962 hgt:164cm ecl:hzl iyr:2018
pid:478415905 eyr:2025 cid:315
ecl:amb hgt:91
iyr:2014 hcl:#cc9d80
byr:1985
pid:561885837 hcl:#7d3b0c
hgt:169cm
byr:1921 iyr:2014 cid:178
eyr:2022 ecl:gry
ecl:#c87497 hcl:5321a2 eyr:2020 hgt:74in
pid:#7a62c6 iyr:1976
eyr:2037
pid:858202391 hgt:162cm
ecl:grn byr:2003
cid:278
iyr:2010 hcl:cbf662
ecl:blu iyr:2012 hgt:183cm hcl:#623a2f pid:848200472 byr:1997 eyr:2027
byr:1942
hgt:164cm
pid:464257339
iyr:2016
hcl:#7d3b0c ecl:gry
iyr:2012 hcl:#ceb3a1
hgt:193cm ecl:amb
pid:667987561 eyr:2024 byr:1960
hgt:187cm
pid:222340640
iyr:2018 eyr:2022
ecl:oth
byr:1957
hcl:#336667 cid:83
eyr:2025 iyr:2015 hcl:#733820
ecl:brn
pid:131195653
hgt:185cm eyr:2026
ecl:amb byr:1998 pid:938587659 hcl:#733820
iyr:2016
ecl:oth pid:300949722
eyr:2028 iyr:2016
byr:1933
hgt:179cm
hcl:#cfa07d
byr:1974 iyr:2019
ecl:hzl hcl:#c0946f eyr:2024 pid:484547079
cid:112
hgt:185cm
eyr:2022 iyr:2018 hcl:#fffffd pid:118568279
hgt:153cm ecl:gry byr:1941 cid:341
iyr:2018
eyr:2027 hcl:#888785
byr:1970 hgt:165cm pid:773715893
ecl:amb
hcl:#623a2f hgt:156cm byr:1938 iyr:2012 pid:745046822
ecl:amb
eyr:2030
iyr:2012
pid:097961857
eyr:2023 hgt:66in hcl:#fffffd byr:1962 ecl:utc
byr:1943 hgt:150cm
iyr:2012
pid:740693353 eyr:2023
hcl:#18171d cid:101 ecl:blu
iyr:2018 pid:183728523 byr:1924 hgt:154cm eyr:2030
cid:167 ecl:blu hcl:#ceb3a1
hgt:69cm
eyr:2025 hcl:z ecl:brn byr:1982 pid:250782159
iyr:2011
byr:1998 iyr:2018 hcl:#341e13 eyr:2022 hgt:157cm pid:497100444 cid:266 ecl:gry
eyr:2027 iyr:2011 hcl:#6b5442 hgt:156cm pid:494073085
byr:1998
ecl:hzl
byr:1947 hcl:#b6652a
iyr:2011 pid:228986686 eyr:2030 hgt:175cm cid:70 ecl:brn
eyr:2026 hgt:159cm
byr:1946 pid:534291476
iyr:2018 ecl:gry cid:225
hcl:#18171d
pid:439665905
cid:311 ecl:amb iyr:2018
eyr:2030
hgt:186cm byr:1950
hcl:#cfa07d
pid:250175056 hcl:#efcc98
byr:1981 cid:262 hgt:154cm ecl:gry iyr:2020 eyr:2027
pid:461335515 iyr:2014 hcl:#f1cf00 hgt:180cm ecl:amb eyr:2027
byr:1956
iyr:2014 eyr:2030 cid:194
pid:234623720 hcl:#733820
hgt:164cm byr:1929
ecl:blu
byr:1992
eyr:2024 hcl:#ef8161 cid:216
ecl:brn hgt:177cm iyr:2018
pid:101726770
hcl:#341e13 hgt:178cm iyr:2016 eyr:2029 byr:1945 pid:045325957 ecl:grn cid:99
ecl:gry
iyr:2012
cid:52 hgt:168cm byr:1943
hcl:#cfa07d
pid:899608935 eyr:2030
cid:241
byr:1934 hgt:161cm eyr:2027 iyr:2011 hcl:#c0946f ecl:amb pid:346857644
iyr:2019 hgt:178cm
hcl:#c0946f byr:1957
eyr:2026
ecl:brn pid:222885240
ecl:blu
eyr:2021 cid:312 hcl:#733820 hgt:186cm iyr:2012 byr:1969
pid:821704316
hcl:#6b5442 cid:159
hgt:180cm
iyr:2018
eyr:2028
ecl:hzl byr:1966
pid:#e0238e
pid:622400994 eyr:2022 hcl:#5b6635 iyr:2012 byr:1980
hgt:190cm ecl:oth
byr:1976 ecl:gry eyr:2020 iyr:2020 hgt:171cm pid:219878671 hcl:#6b5442
hgt:163cm byr:1968
pid:003521394 ecl:oth
iyr:2010
cid:61 hcl:#888785
cid:115 pid:810722029 hgt:166cm byr:1955
ecl:blu eyr:2030 iyr:2018
hgt:176cm
eyr:2025
pid:617393532 hcl:#733820 byr:1975 iyr:2018 ecl:grn
hcl:#733820 byr:1979 pid:838168666
hgt:190cm ecl:oth cid:330
eyr:2029 iyr:2018
eyr:1940 hgt:67cm iyr:2009 ecl:gry pid:#e76a62 byr:2020 hcl:z
hgt:190cm ecl:brn pid:396113351
byr:1956 iyr:2010
hcl:#6b5442 eyr:2024
cid:256
hcl:#efcc98
hgt:178cm byr:1984 iyr:2013 pid:752620212 eyr:2021 ecl:gry
iyr:2014 hcl:#a97842
hgt:166cm ecl:blu eyr:2024
byr:1935
pid:836748873
cid:236 ecl:amb hgt:168cm iyr:2010 hcl:#602927 byr:1950 eyr:2026 pid:404810674
eyr:2030 ecl:grn
byr:1975 pid:064596263 hgt:193cm
iyr:2019 cid:71 hcl:#a97842
iyr:2014
pid:298386733 hcl:#c0946f
hgt:180cm ecl:hzl cid:115 byr:1940 eyr:2023
iyr:1960 hgt:139 ecl:#9db7b8 byr:1980 pid:#ef597b cid:54 eyr:2028 hcl:fdcda3
iyr:2015 byr:1954 ecl:blu hgt:62in hcl:#ceb3a1 pid:253593755 eyr:2028
eyr:2025 ecl:blu pid:216388098 iyr:2017 byr:1968 hgt:151cm hcl:#602927
eyr:2022 hcl:#a97842
pid:606979543 iyr:2013 ecl:grn cid:63
hgt:186cm byr:1992
ecl:gry
hgt:168cm hcl:#18171d iyr:2017 pid:670898814 byr:1983
eyr:2022
hgt:155cm ecl:grn iyr:2012 pid:837979074 eyr:2024 hcl:#888785 byr:1972
iyr:2015 pid:970743533 hcl:#866857 eyr:2027
byr:1921 ecl:brn
eyr:2022
hgt:160cm
byr:1964 hcl:#efcc98 iyr:2019 ecl:oth pid:141923637
byr:2029 pid:3313111652 ecl:brn eyr:2034
iyr:2013 hgt:193cm hcl:z
pid:853890227 eyr:2029
hcl:#efcc98 iyr:2021 byr:2003 ecl:#037c39 hgt:160cm
iyr:1927
byr:1992
eyr:2030
hcl:#efcc98
ecl:amb hgt:152cm pid:436765906
iyr:2014
hcl:#c0946f pid:207052381
eyr:2024 ecl:hzl
hgt:177cm
byr:1923
ecl:blu
iyr:2014
eyr:2025 hgt:165cm
hcl:#733820 pid:343011857 byr:1967
ecl:xry
eyr:2028
iyr:2011 hgt:166in hcl:#c0946f
pid:805297331
cid:167 byr:1926
byr:1947
pid:468012954 eyr:2026 ecl:oth iyr:2018 hgt:170cm hcl:#b6652a
hcl:#6b5442 ecl:brn
hgt:180cm cid:233
pid:029789713
byr:1920 iyr:2010 eyr:2024
iyr:2010 eyr:2027
hgt:156cm
hcl:#c0946f
byr:1960 pid:312723130 ecl:hzl
eyr:2023 byr:1959 iyr:2010 hgt:186cm pid:066768932 ecl:grn hcl:#602927 cid:310
eyr:2030 pid:460535178 hgt:171cm ecl:gry iyr:2020 byr:1934 hcl:#888785
hgt:64cm eyr:2021 byr:1995 cid:336
ecl:gmt pid:926714223 iyr:2017 hcl:#18171d
eyr:2022 iyr:2010
ecl:grn pid:285994301 cid:215
hgt:186cm byr:1978
hgt:63in hcl:#866857
pid:386128445 iyr:2020 byr:1971 eyr:2021 ecl:gry
hgt:183cm hcl:#733820 iyr:2015
ecl:blu pid:216205626 eyr:2022 byr:1941
cid:150 ecl:amb pid:872515243 byr:1926
eyr:1996
hcl:#dedc39 hgt:67in iyr:2020
byr:1927 ecl:brn cid:153 iyr:2011
pid:165190810 hcl:#fffffd
eyr:2028 hgt:64in
pid:502603734
byr:1966 iyr:2015 hgt:176cm cid:205 ecl:brn hcl:#fffffd eyr:2021
hcl:#18171d hgt:158cm byr:1943 iyr:2019
pid:058840094
eyr:2023
byr:1962 hcl:#b6652a ecl:grn
cid:297
iyr:2010 pid:990422650
hgt:154cm eyr:2020
eyr:1934 iyr:2011
ecl:gry
hcl:z byr:2004 hgt:63cm pid:6173356201
pid:329432364 eyr:2029
ecl:grn hcl:#18171d iyr:2013
hgt:158cm byr:1960
hcl:#efcc98 iyr:2016 hgt:186cm cid:215
pid:852781253 eyr:2027 ecl:blu byr:1937
hcl:#623a2f ecl:gry iyr:2020 byr:1972 hgt:182cm pid:073426952 eyr:2027
hcl:#3317b9 byr:1950 pid:304511418 hgt:177cm cid:124 eyr:2020 ecl:hzl iyr:2014
eyr:2029
pid:034754507 byr:1936
cid:265 ecl:#b50997 hgt:183cm
hcl:#623a2f iyr:1924
eyr:2024 byr:1927 cid:243 ecl:gry hcl:#6b5442 pid:714355627 hgt:160cm
iyr:2016
hgt:152cm
ecl:gry hcl:#a97842
eyr:2029 byr:1952
pid:555308923 iyr:2010
byr:2008
pid:19681314 hgt:180in iyr:2030 ecl:gry cid:272
eyr:2023
hcl:#b6652a
cid:234
iyr:2014 byr:1940 ecl:hzl pid:042231105 hcl:#3bf69c hgt:172cm eyr:2029
hcl:#efcc98 pid:831567586 hgt:190cm iyr:2017
byr:1966 eyr:2024 ecl:blu
hcl:#341e13 ecl:blu
eyr:2022 cid:161 pid:197839646 iyr:2014
hcl:#cfa07d
byr:1957
iyr:2019 hgt:181cm
pid:543775141 ecl:oth eyr:2021
hcl:z
pid:#596c41 eyr:2035
byr:2008 iyr:1975
ecl:#c66ee6
hgt:150in
ecl:grn
hcl:#7d3b0c iyr:2016
pid:804255369 eyr:2028 byr:1983 hgt:69in cid:82
eyr:2022
iyr:2013 hgt:191cm ecl:gry
hcl:#a97842 pid:186827268 byr:1969
pid:871672398 eyr:2026 byr:1946 ecl:oth
iyr:2015
hcl:#866857 hgt:185cm
byr:1973
hgt:150cm
pid:905076707
iyr:2017
hcl:#2edf01 ecl:oth cid:221 eyr:2026
eyr:2024 ecl:grn pid:955444191 hcl:z iyr:2015 byr:2008 hgt:151cm
byr:1958 hcl:#fffffd pid:218986541 cid:203 ecl:brn hgt:154cm
iyr:2014
eyr:2026
hcl:#623a2f byr:1964 ecl:oth iyr:2010 pid:525843363 hgt:164cm eyr:2025
ecl:blu iyr:2013 hgt:193cm byr:1990 pid:612387132 hcl:#18171d cid:280 eyr:2028
ecl:oth eyr:2022
pid:110447037 hgt:187cm byr:1967 hcl:#efcc98
byr:1930
eyr:2026 hgt:159cm
iyr:2011
ecl:hzl hcl:#6b5442 pid:923471212
cid:350
eyr:2029 pid:823592758 iyr:2018
ecl:grn byr:1972 hgt:167cm hcl:#18171d
cid:76 eyr:2027 hcl:#6b5442 pid:099579798 byr:1930
iyr:2020
ecl:gry hgt:153cm
byr:1957 ecl:brn
hcl:z iyr:2016 pid:352677969 hgt:189cm
eyr:2029
cid:143 eyr:2035 pid:602952079
ecl:#9b73f0 hcl:#602927
iyr:2022 byr:1975
hgt:174cm
byr:1971 pid:741305897 hgt:192cm
ecl:amb hcl:#888785 eyr:2028 iyr:2011
ecl:oth iyr:2016
byr:1942 hgt:189cm hcl:#888785 eyr:2024 pid:054290182
hcl:#a97842
byr:1945
ecl:amb pid:370849304
eyr:2028
iyr:2016 hgt:168cm
hgt:154cm iyr:2015 eyr:2030 byr:1952 ecl:hzl hcl:#341e13 pid:996518075
byr:1941 ecl:amb iyr:2014
hcl:#fffffd pid:560990286 eyr:2022 hgt:173cm
ecl:blu byr:1974
hgt:150cm hcl:#ceb3a1 eyr:2020 iyr:2013
pid:827415351
hcl:#623a2f eyr:2027 iyr:2011 pid:913199234 ecl:oth
byr:1990 hgt:178cm
ecl:blu byr:1989 hcl:#b6652a
eyr:2026 pid:724881482 hgt:185cm iyr:2014
cid:115 pid:255002731 eyr:2025 ecl:amb
byr:1934 iyr:2020 hcl:#7d3b0c
hgt:150cm byr:1969 ecl:blu iyr:2023
hcl:#866857 pid:754288625 eyr:2029
iyr:2011 hcl:#7d3b0c ecl:hzl
byr:1930
hgt:188cm
eyr:2023
pid:256556076 cid:136
iyr:2025 byr:1978
ecl:#fe30a9 hcl:#efcc98 eyr:2029
pid:392032459 hgt:178cm
eyr:2027 iyr:2017 hgt:160in
byr:1990 pid:131099122 hcl:#623a2f ecl:amb
ecl:grn
byr:1978
eyr:2029 hcl:#18171d
hgt:165cm pid:172369888
cid:93
iyr:2011
ecl:hzl
hcl:#733820 iyr:2010 eyr:2029 pid:127253449
hgt:156cm
byr:1963
hcl:#6c8530
iyr:2020
byr:1929 eyr:2021 hgt:177cm ecl:oth pid:347925482
eyr:2037 iyr:2026
pid:163cm
hgt:174in byr:2007 hcl:c1305f cid:134
ecl:#0cf85c
iyr:2011 pid:033811215
hcl:#a97842 byr:2002 eyr:2021 hgt:186cm
ecl:brn
hcl:#a97842
iyr:2020 eyr:2029 byr:1972 pid:535511110 hgt:160cm ecl:oth
ecl:grn cid:89 hgt:193cm pid:73793987 iyr:2021 eyr:2027 byr:1939 hcl:z
hcl:#623a2f
hgt:182cm cid:154
pid:873863966 iyr:2018 byr:1999 ecl:brn eyr:2031
iyr:2014 eyr:2029
cid:71 hcl:#fffffd byr:1924 hgt:63in
ecl:gry pid:897972798
hgt:76cm
hcl:z eyr:1955
iyr:2012 byr:2001 pid:9425090 ecl:hzl
eyr:2021
pid:501861442
ecl:grn hcl:#d71ae9
byr:1977
hgt:167cm iyr:2015
iyr:2014
hgt:170cm ecl:gry byr:1928 cid:314 hcl:#602927 eyr:2029
pid:836710987
eyr:2027 hcl:#efcc98 ecl:amb iyr:2016 byr:1995 pid:603705616 hgt:179cm
eyr:2030 hcl:#602927 cid:105 byr:1943 ecl:hzl
pid:381601507
hgt:188cm iyr:2020
iyr:2011
byr:1993 hcl:#c0946f pid:292649640 hgt:139 ecl:hzl cid:268
eyr:1999
cid:339 byr:1928
ecl:brn eyr:2022 hcl:#733820 hgt:191cm pid:282733347 iyr:2019
hgt:176cm
byr:1935 ecl:brn cid:252 eyr:2023 pid:105060622 iyr:2020 hcl:#18171d
ecl:hzl eyr:2029
hgt:193cm pid:770254253
hcl:#efcc98 iyr:2020 byr:1926
pid:977785261 eyr:2022 iyr:2015 byr:1978
hcl:#733820 hgt:172cm
ecl:brn
byr:2021
hgt:160in
ecl:gmt
eyr:2032 cid:345 pid:179cm
hcl:8f5c13 iyr:2029
iyr:2018 hgt:182cm ecl:gry
pid:897076789 eyr:2023 hcl:#866857
byr:1980
hgt:88 eyr:2039 cid:99 byr:2007 hcl:a1bb42 ecl:#a2f6bb
pid:2264966188
iyr:2022
iyr:2012 cid:59 ecl:gry eyr:2021
byr:1931
hgt:172cm hcl:#7d3b0c pid:862416147
byr:1962 eyr:2025
ecl:grn
hcl:#866857 hgt:180cm iyr:2014 pid:313647071
eyr:2030 hgt:157cm byr:1985
iyr:2020
hcl:#7d3b0c pid:911544768
ecl:grn
hgt:175cm
byr:1938
iyr:2020 ecl:amb hcl:#602927 eyr:2026 pid:144411560
iyr:2019 ecl:amb hcl:#888785 eyr:2025 hgt:187cm
pid:942054361 byr:1939
cid:168 pid:722146139 byr:1952 ecl:grn
iyr:2014 hgt:97
hcl:z
eyr:2023
eyr:2024 pid:567528498 ecl:gry iyr:2012 byr:1990
hcl:#733820 hgt:193cm
cid:293
hcl:#bc352c pid:321838059 byr:1930 hgt:178cm cid:213 eyr:2023 ecl:amb
iyr:2017
hgt:173cm byr:1925 pid:070222017 iyr:2013 hcl:#ceb3a1 ecl:gry eyr:2024"""
I then split() the string into a list, split_input, using two newline characters as the delimiter:
split_input = raw_input.split("\n\n")
Here’s a sample of the result:
['pid:827837505 byr:1976\nhgt:187cm\niyr:2016\nhcl:#fffffd\neyr:2024',
'hgt:189cm byr:1987 pid:572028668 iyr:2014 hcl:#623a2f\neyr:2028 ecl:amb',
'pid:#e9bf38 hcl:z iyr:2029 byr:2028 ecl:#18f71a hgt:174in eyr:2036',
'hcl:#cfa07d byr:1982 pid:573165334 ecl:gry eyr:2022 iyr:2012 hgt:180cm',
'cid:151 hcl:#c0946f\necl:brn hgt:66cm iyr:2013 pid:694421369\nbyr:1980 eyr:2029',
...
'cid:168 pid:722146139 byr:1952 ecl:grn\niyr:2014 hgt:97\nhcl:z\neyr:2023',
'eyr:2024 pid:567528498 ecl:gry iyr:2012 byr:1990\nhcl:#733820 hgt:193cm\ncid:293',
'hcl:#bc352c pid:321838059 byr:1930 hgt:178cm cid:213 eyr:2023 ecl:amb\niyr:2017',
'hgt:173cm byr:1925 pid:070222017 iyr:2013 hcl:#ceb3a1 ecl:gry eyr:2024']
At this point, each item in the list had its individual components delimited by a mix of spaces and newlines. I used this line of code to convert and newlines to spaces:
split_input_2 = [string.replace("\n", " ") for string in split_input]
Here’s a sample of the result:
['pid:827837505 byr:1976 hgt:187cm iyr:2016 hcl:#fffffd eyr:2024',
'hgt:189cm byr:1987 pid:572028668 iyr:2014 hcl:#623a2f eyr:2028 ecl:amb',
'pid:#e9bf38 hcl:z iyr:2029 byr:2028 ecl:#18f71a hgt:174in eyr:2036',
'hcl:#cfa07d byr:1982 pid:573165334 ecl:gry eyr:2022 iyr:2012 hgt:180cm',
...
'cid:168 pid:722146139 byr:1952 ecl:grn iyr:2014 hgt:97 hcl:z eyr:2023',
'eyr:2024 pid:567528498 ecl:gry iyr:2012 byr:1990 hcl:#733820 hgt:193cm cid:293',
'hcl:#bc352c pid:321838059 byr:1930 hgt:178cm cid:213 eyr:2023 ecl:amb iyr:2017',
'hgt:173cm byr:1925 pid:070222017 iyr:2013 hcl:#ceb3a1 ecl:gry eyr:2024']
I now had an list of single-line strings, each one representing a passport, with each passport’s information delimited by spaces.
My next step was to split() each passport string into a list:
split_input_3 = [string.split() for string in split_input_2]
The result was a master list of password lists. Here’s a sample:
[['pid:827837505',
'byr:1976',
'hgt:187cm',
'iyr:2016',
'hcl:#fffffd',
'eyr:2024'],
['hgt:189cm',
'byr:1987',
'pid:572028668',
'iyr:2014',
'hcl:#623a2f',
'eyr:2028',
'ecl:amb'],
['pid:#e9bf38',
'hcl:z',
'iyr:2029',
'byr:2028',
'ecl:#18f71a',
'hgt:174in',
'eyr:2036'],
...
['hcl:#bc352c',
'pid:321838059',
'byr:1930',
'hgt:178cm',
'cid:213',
'eyr:2023',
'ecl:amb',
'iyr:2017'],
['hgt:173cm',
'byr:1925',
'pid:070222017',
'iyr:2013',
'hcl:#ceb3a1',
'ecl:gry',
'eyr:2024']]
I wanted to convert each password list into a dictionary, so I wrote this function…
def convert_to_dictionary(password_list):
dictionary = {}
for item in password_list:
item_parts = item.split(":")
key = item_parts[0]
value = item_parts[1]
dictionary[key] = value
return dictionary
…which I then used that ever-so-useful Python tool, the list comprehension:
passports = [convert_to_dictionary(item) for item in split_input_3]
I now had a list of passport dictionaries:
[{'pid': '827837505',
'byr': '1976',
'hgt': '187cm',
'iyr': '2016',
'hcl': '#fffffd',
'eyr': '2024'},
{'hgt': '189cm',
'byr': '1987',
'pid': '572028668',
'iyr': '2014',
'hcl': '#623a2f',
'eyr': '2028',
'ecl': 'amb'},
{'pid': '#e9bf38',
'hcl': 'z',
'iyr': '2029',
'byr': '2028',
'ecl': '#18f71a',
'hgt': '174in',
'eyr': '2036'},
{'hcl': '#cfa07d',
'byr': '1982',
'pid': '573165334',
'ecl': 'gry',
'eyr': '2022',
'iyr': '2012',
'hgt': '180cm'},
...
{'hcl': '#bc352c',
'pid': '321838059',
'byr': '1930',
'hgt': '178cm',
'cid': '213',
'eyr': '2023',
'ecl': 'amb',
'iyr': '2017'},
{'hgt': '173cm',
'byr': '1925',
'pid': '070222017',
'iyr': '2013',
'hcl': '#ceb3a1',
'ecl': 'gry',
'eyr': '2024'}]
Strategy
With the input data massaged into a decent data structure, it was time to test the passports to see if they were valid. Valid passports have have all the required keys.
I wrote this function to test the validity of a given passport:
def is_valid_passport(passport):
has_birth_year = "byr" in passport
has_issue_year = "iyr" in passport
has_expiration_year = "eyr" in passport
has_height = "hgt" in passport
has_hair_color = "hcl" in passport
has_eye_color = "ecl" in passport
has_passport_id = "pid" in passport
has_country_id = "cid" in passport
return (
has_birth_year and
has_issue_year and
has_expiration_year and
has_height and
has_hair_color and
has_eye_color and
has_passport_id
)
With is_valid_passport() written, I could apply it to every passport by way of a list comprehension:
valid_passports = [passport for passport in passports if is_valid_passport(passport)]
print(len(valid_passports))
My result: 228. I entered it into the solution text field, and Advent of Code told me that I was correct! It was time for part two.
The Day 4 challenge, part two

The challenge
Here’s the text of part two:
The line is moving more quickly now, but you overhear airport security talking about how passports with invalid data are getting through. Better add some data validation, quick!
You can continue to ignore the cid field, but each other field has strict rules about what values are valid for automatic validation:
byr (Birth Year) – four digits; at least 1920 and at most 2002.iyr (Issue Year) – four digits; at least 2010 and at most 2020.eyr (Expiration Year) – four digits; at least 2020 and at most 2030.hgt (Height) – a number followed by either cm or in:
- If
cm, the number must be at least 150 and at most 193.
- If
in, the number must be at least 59 and at most 76.
hcl (Hair Color) – a # followed by exactly six characters 0–9 or a–f.ecl (Eye Color) – exactly one of: amb blu brn gry grn hzl oth.pid (Passport ID) – a nine-digit number, including leading zeroes.cid (Country ID) – ignored, missing or not.
Your job is to count the passports where all required fields are both present and valid according to the above rules. Here are some example values:
byr valid: 2002
byr invalid: 2003
hgt valid: 60in
hgt valid: 190cm
hgt invalid: 190in
hgt invalid: 190
hcl valid: #123abc
hcl invalid: #123abz
hcl invalid: 123abc
ecl valid: brn
ecl invalid: wat
pid valid: 000000001
pid invalid: 0123456789
Here are some invalid passports:
eyr:1972 cid:100
hcl:#18171d ecl:amb hgt:170 pid:186cm iyr:2018 byr:1926
iyr:2019
hcl:#602927 eyr:1967 hgt:170cm
ecl:grn pid:012533040 byr:1946
hcl:dab227 iyr:2012
ecl:brn hgt:182cm pid:021572410 eyr:2020 byr:1992 cid:277
hgt:59cm ecl:zzz
eyr:2038 hcl:74454a iyr:2023
pid:3556412378 byr:2007
Here are some valid passports:
pid:087499704 hgt:74in ecl:grn iyr:2012 eyr:2030 byr:1980
hcl:#623a2f
eyr:2029 ecl:blu cid:129 byr:1989
iyr:2014 pid:896056539 hcl:#a97842 hgt:165cm
hcl:#888785
hgt:164cm byr:2001 iyr:2015 cid:88
pid:545766238 ecl:hzl
eyr:2022
iyr:2010 hgt:158cm hcl:#b6652a ecl:blu byr:1944 eyr:2021 pid:093154719
Count the number of valid passports – those that have all required fields and valid values. Continue to treat cid as optional. In your batch file, how many passports are valid?
Strategy
In part one, it was about testing for the presence of required keys. This time, it was about testing for valid values.
To that end, I wrote this function…
def has_valid_values(passport):
has_valid_birth_year = 1920 <= int(passport["byr"]) <= 2002
has_valid_issue_year = 2010 <= int(passport["iyr"]) <= 2020
has_valid_expiration_year = 2020 <= int(passport["eyr"]) <= 2030
has_valid_height = False
height_units = passport["hgt"][-2:]
if height_units == "cm":
height = int(passport["hgt"][:-2])
has_valid_height = 150 <= height <= 193
elif height_units == "in":
height = int(passport["hgt"][:-2])
has_valid_height = 59 <= height <= 76
def is_valid_hex_string(string):
test_value = string.lower()
is_valid = True
for character in string:
if character not in "0123456789abcdef":
is_valid = False
break
return is_valid
has_valid_hair_color = False
if len(passport["hcl"]) == 7:
digits = passport["hcl"][1:]
has_valid_hair_color = is_valid_hex_string(digits)
has_valid_eye_color = passport["ecl"] in ["amb", "blu", "brn", "gry", "grn", "hzl", "oth"]
def is_valid_passport_id(value):
is_valid = False
if len(value) == 9:
is_valid = True
for character in value:
if character not in "0123456789":
is_valid = False
break
return is_valid
has_valid_passport_id = is_valid_passport_id(passport["pid"])
return (
has_valid_birth_year and
has_valid_issue_year and
has_valid_expiration_year and
has_valid_height and
has_valid_hair_color and
has_valid_eye_color and
has_valid_passport_id
)
…which I then used in a list comprehension, which served as a filter on the validated passports from part one:
truly_valid_passports = [passport for passport in valid_passports if has_valid_values(passport)]
print(len(truly_valid_passports))
My result was 175, which was correct. Day 4 was done!



 TinyColor is a fantastic JavaScript library that can help you out with a whole bunch of tasks when you’re working with colors. This article takes a quick look at this more-useful-than-you-might-think library.
TinyColor is a fantastic JavaScript library that can help you out with a whole bunch of tasks when you’re working with colors. This article takes a quick look at this more-useful-than-you-might-think library.